2009年 12月 的归档
nginx 对某些 User_Agent 进行限速的方法
本文为nginx 禁止某个 User_Agent 的方法的姊妹篇,不知所云的话,建议先看看这文。
由于之前已经将某个特别疯狂的迅雷的User_Agent给封掉了,所以最近一段时间,我的那源服务器也运行地比较稳定,但是今天,Linux Deepin 9.12正式发布了,由于我给Deepin做了一个iso的镜像,所以服务器又经历了一个访问高峰,如下图:

从这里也可以看出Linux Deepin的受欢迎程度,哈哈。
可以看到从11:00以后,100M的带宽就已经被完全撑满了。。。一看日志,大部分又是迅雷干的,但这次迅雷不是用某个特定的UA来访问了,而是各有变化,但是却都包含MSIE,哈哈。
当然IE用户直接访问的话,也会有这个MSIE,但是没办法,为了保全Ubuntu APT-HTTP的合法权益,只能限制一下MSIE了。
但是怎么限制呢?总不能人家用MSIE的连主页面都打不开吧?哈哈,最好的办法就是限速,于是,有了这个配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
server { listen 80; server_name ubuntu.srt.cn; access_log /var/log/nginx/mirror.access.log; location / { root /data/mirrors; autoindex on; index index.html index.htm; if ($http_user_agent ~ "MSIE") { limit_rate 2k; } if ($http_user_agent ~ "Mozilla/4.0\ \(compatible;\ MSIE\ 6.0;\ Windows\ NT\ 5.1;\ SV1;\ .NET\ CLR\ 1.1.4322;\ .NET\ CLR\ 2.0.50727\)") { return 404; } } error_page 500 502 503 504 /50x.html; location = /50x.html { root /var/www/nginx-default; } } |
让我们邪恶的看一下效果,哈哈:
wget的默认UA的时候:
|
1 2 3 4 5 6 7 8 9 10 11 |
$ wget --no-cache http://u.srt.cn/ubuntu/ls-lR.gz -O /dev/null --14:08:28-- http://u.srt.cn/ubuntu/ls-lR.gz => `/dev/null' 正在解析主机 u.srt.cn... 211.155.227.167 Connecting to u.srt.cn|211.155.227.167|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:8,051,367 (7.7M) [text/plain] 100%[====================================>] 8,051,367 6.34M/s 14:08:29 (6.33 MB/s) - `/dev/null' saved [8051367/8051367] |
UA里含有MSIE的时候:
|
1 2 3 4 5 6 7 8 9 |
$ wget --no-cache --user-agent="Something with MSIE; bla bla" http://u.srt.cn/ubuntu/ls-lR.gz -O /dev/null --14:07:59-- http://u.srt.cn/ubuntu/ls-lR.gz => `/dev/null' 正在解析主机 u.srt.cn... 211.155.227.167 Connecting to u.srt.cn|211.155.227.167|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:8,051,367 (7.7M) [text/plain] 0% [ ] 49,152 2.08K/s ETA 1:02:38 |
某个该死的特定UA:
|
1 2 3 4 5 6 7 |
$ wget --no-cache --user-agent="Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)" http://u.srt.cn/ubuntu/ls-lR.gz -O /dev/null --14:09:22-- http://u.srt.cn/ubuntu/ls-lR.gz => `/dev/null' 正在解析主机 u.srt.cn... 211.155.227.167 Connecting to u.srt.cn|211.155.227.167|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 404 Not Found 14:09:22 错误 404:Not Found。 |
从上图也可以看到,做了这个设置以后,从14:00左右开始,服务器的流量虽然还是比较大,但是已经趋于正常了。
所以,偶尔要从我源里下东西的同学,可以用firefox直接下载,也可以用axel或者wget之类的工具下,但是千万别用IE相关的工具,不然,后果自负,哈哈~
开源的命令行OCR软件──tesseract
tesseract-ocr是一个跨平台开源的OCR软件(Optical Character Recognition,光学字符识别),它历史悠久,早期是HP实验室的项目,现托管于google code。
大部分常用的linux发行版,应该都在源里包含了此软件,所以ubuntu下只需要 sudo apt-get install tesseract-ocr tesseract-ocr-eng 就可以安装了,注意必须安装 tesseract-ocr-eng 这个是识别英文字符所必须的数据文件。而在gentoo下,也只需要 emerge app-text/tesseract 就可以了,但是也必须给这个包添加 linguas_en 这个use,才会安装所需要的数据文件。
关于数据文件,还得交代一下,其实tesseract在2.0版以后,已经有了学习能力了,如果你想提高某个字体的识别率,或者识别不在默认语言包里的UTF-8字符(比如中文)的话,可以安装这个方法来训练出自己的数据文件。
这个OCR软件能干嘛呢?典型地应用就是识别验证码,哈哈。所以以这个为例,来介绍一下使用方法,先来看看这几个验证码(可“图片另存为”,然后自行测试):
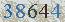

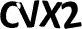
这几个都是用默认的数据文件能正确识别的例子,由于tesseract只识别tiff格式的图片文件,所以识别之前,需要将图片先转成tif格式,具体如下:
|
1 2 3 4 5 |
$ convert cnblogs.com.jpe ppm:- | ppm2tiff yzm.tif $ tesseract yzm.tif out Tesseract Open Source OCR Engine $ cat out.txt 1750 |
同时,也有些比较难的验证码,是程序不能正确识别的,如下几个就是例子:
虽然识别的正确性不是非常高,但是已经很不错了,哈哈。
PS: 有没有人训练个识别google验证码专用的数据文件?
grub故障一例
昨天,心血来潮进了一下许久没有使用过的ubuntu,然后顺手给它升级了一下,发现这个把月已经有200多M的更新了,其中也包括内核在内。
于是开开心心地dist-upgrade完了,也没啥异常。但是到了昨晚,再开机的时候,发现机器没有正常显示grub菜单,而是直接进入了GRUB>这样的命令行。幸好我还记得几个grub的命令,瞎蒙地还算是启动了我的gentoo,然后上网一google,发现这个问题和我之前把文件系统全面升级到ext4有关:在升级了文件系统以后,再升级内核的话,就会导致grub找不到某些文件而无法正常工作。
解决办法就是在gentoo里chroot到ubuntu的/分区(因为我的grub是在ubuntu下安装的),然后执行:
|
1 |
grub-install --recheck /dev/sda |
如果没报什么错误的话,那恭喜你,你的grub又回来了。
当然,有人会问:如果我硬盘上没有gentoo或者记不住grub命令无法启动的话,怎么办呢?其实很简单,你只要随便找个linux的LiveCD,或者U盘系统之类的,启动以后,就一样可以chroot了。
哈哈,linux很灵活,所以基本是不死的(当然你要对它有足够了解才行)~
python代码风格检查工具──pylint
pylint是一个python代码检查工具,可以帮助python程序员方便地检查程序代码的语法和风格,通过这个工具,可以使你的python代码尽量保持完美,哈哈。
具体可以检查什么东西呢?
比如你写了 from XXX import * 了,它就会提示你这样import是不好的。
比如你操作符的前后没有空格,它也会提示你。
比如逗号后面没跟空格也会。
还有你import了没用到的模块,定义了没使用的变量等也会提示。
还有你的变量名是否符合规范也会提示。
总之它提示的内容很多很全面,而且它最后会给出一个所检查的代码的总体分数,如果能达到满分10分的话,简直就是神作了,因为pylint本身的代码也才9.5分左右,哈哈。
比较惨的是,TX发现这个工具以后,检查了几个python项目的分数,都不是很高,我那gmbox得了2分多点,还算是高的。不过,经过一番优化,现在的gmbox已经有6.64分,及格了,哈哈。。
值得一提的是,pylint不仅可以像默认那样输出字符结果,还可以彩色化输出,甚至还可以输出HTML和visual studio的格式。具体用法可以参见man页和这个文档。
简单的WP备份脚本
现在,写blog的人是越来越多了;这部分人里,自己建站的也越来越多了;又在这部分人里,用WP来建的也越来越多了。
而建过站的人,都知道备份的重要性。但是手工备份又显然太麻烦了,所以我写了这个脚本来自动备份,放cron里以后,基本上就不用去关心什么了,哈哈,不过在加crontab的时候,要注意用户,如果是用root跑,可能会因为读不到当前用户的key而备份失败哦。
条件是你的空间支持ssh登录,并且事先做好了rsa公钥,登录的时候不需要输入密码。
此脚本会生成两个文件,一个是文件的打包,一个是数据库的打包。上脚本吧:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
#!/bin/sh #WP备份脚本 #方便地备份wordpress的文件及数据库(限mysql) #作者: bones7456 #需要事先设置好这个HOST的rsa key 不然无法用ssh登录 HOST="gnometwe@li2z.cn" #远程的WP文件所在目录,此目录下要有 wp-config.php REMOTE_PATH="www/li2z" #本地保存目录(最好是绝对路径),留空为当前目录 LOCAL_PATH="/home/lily/li2z.backup" #备份文件的前缀,默认自动按时间生成 PRE=`date +%F-%H-%M-%S` [ -z $LOCAL_PATH ] || cd $LOCAL_PATH #先备份文件 ssh $HOST "cd $REMOTE_PATH; tar cf - -X exclude ." | gzip > $PRE.tar.gz #从文件取得数据库信息 tar zxvf $PRE.tar.gz ./wp-config.php if [ -f wp-config.php ];then DB_NAME=`grep "^define('DB_NAME'" wp-config.php | cut -d\' -f 4` DB_USER=`grep "^define('DB_USER'" wp-config.php | cut -d\' -f 4` DB_PASSWORD=`grep "^define('DB_PASSWORD'" wp-config.php | cut -d\' -f 4` rm wp-config.php else echo "Something wrong ..." exit 1 fi #再备份数据库 ssh $HOST mysqldump -u${DB_USER} -p${DB_PASSWORD} $DB_NAME | gzip > $PRE.sql.gz #这个可选,删除15天前的备份文件 #要打开的话,记得建个专门的目录存放备份,以免误删其他文件 #find . -maxdepth 1 -name "*.gz" -mtime +15 -exec rm {} \; |
PS: 稍作修改应该也可以用于非WP的blog系统。
关于网上银行
今天,我几乎是花了整个下午的时间,做了一件本该很简单的事情——用网上银行买了两张机票。就来说说我在linux下使用网银的经历吧。
今年我新婚不久,想在这个冬天带着老婆去海南渡蜜月,计划了很久,由于经费不是充裕,决定不用任何旅行社,来次完全自主的自由行。
这不,今天选好了机票,在航空公司的网站下了订单,到了支付环节,卡住了,本打算用老婆的信用卡付钱的,但是偏偏这个航空公司是不支持宁波银行的信用卡的。
无奈,看了一下,支持招商银行,心想正好我也有张招行的卡,就用这个吧。但是试了几次失败以后,终于明白我的招行卡根本没有开通网上银行的支付功能,怎么办呢?打了95555咨询以后,说必须带身份证和卡去柜台申请,获得授权码才可以开通网上支付功能。
没办法,咱就去呗,幸好银行周末还是上班的,离住处也不是非常远(虽然也不算近)。
于是兴冲冲跑到银行,填表,还算顺利,没几分钟就办好回来了。得到一个授权码,说是可以凭这玩意获得一个数字证书文件,而且授权码只能使用一次。
由于之前一直在linux下,我也知道网银和航空公司的网站对linux和firefox的支持都很有限,于是操作都在vbox的虚拟XP里进行,所以到了这一步,虽然也曾听闻招行的网银不能在vbox下使用,但是心里仍然存在侥幸心理,万一能的话,就不用重启了,再说,真不能用的话,到时候提示了再重启也不迟嘛。于是,悲剧就这么发生了:我在vbox里下载网银的一个什么客户端,然后用刚申请的授权码启用了数字证书,一切都很顺利,正当我心里暗爽的时候,问题终于发生了:我登陆不了。。。而授权码已经使用,并且和本系统(Vbox的Guest系统)绑定了,但这个客户端是在登录的时候,是会检测系统的键盘状态的,也就是说,不管是USE外接键盘、屏幕软键盘还是远程桌面连接过去的键盘,都会因为传说中的安全问题,而被禁用。当然虚拟机的键盘也就被禁用了。
于是,我只能再跑一次银行,再填表,再申请一个授权码,回来重启到真正的XP下面,再安装客户端,然后获取数字证书,才算完成了支付过程。期间,那订单都超时作废了好几次了。
综上所述,我对现有的网银有如下抱怨:
抱怨1:现在国内的网上支付业务,没有一个绝对权威的机构统一管理,导致商家和银行的合作不全面,这样才导致了部分航空公司支持这几个银行的卡,另一些又支持那些银行的卡。为什么不成立一个类似“银联”的机构,把这个接口规范化呢?如果今天航空公司支持宁波银行的卡的话,也就不会有后面这一堆破事了。
抱怨2:这也是linuxer的普遍抱怨,网银对linux的支持太不友好了,又是ActiveX控件,又是exe的客户端,这些落后的技术到底要折磨我们到何时呢?这个老生常谈的问题也就不多说了。
抱怨3:就是针对招行的了,既然你不允许vbox的系统登录客户端,为什么在客户端里启用证书的过程中完全没有提示呢?这也是我今天最火的事。先不说你判断物理键盘进行安全认证有没有道理,至少,都是同一个程序,要检测的的话,完全有可能在程序一启动的时候,就进行运行环境的检测,而且在数字证书的签发过程中也是必然会进行系统信息的收集的(因为证书和系统是一一对应的),但是程序在启动过程和信息收集的过程都没有进行提示,却在数字证书安装完了以后,登录的时候再提示。也就是说,这时,授权码已经失效了,而且数字证书的备份也要在登录以后才能进行,刚刚好在这个节骨眼上,给你卡住了。这还能算是经过人的大脑设计出来的程序吗?
好了,遇到这事,咱也只能抱怨抱怨了事了,呵呵。接下来还是很期待这次三亚蜜月行的,哈哈。
PS:支付完了以后,在IE下写这文,发现IE下的WP后台真难看,哈哈,不过拿sogou拼音打字确实挺快。
监视文件系统的一举一动 ── inotifywait
某天,TX大侠说他找不到awn的配置文件在什么地方,问我知道不?而我只是在N年前用过一下下awn而已,所以,理所当然地不知道了。后来,我们想了一个土办法:
在$HOME下先执行一次
|
1 |
tree -as > /tmp/before |
然后在awn的界面里修改一下配置,再在$HOME下再执行一次
|
1 |
tree -as > /tmp/after |
然后再
|
1 |
diff /tmp/before /tmp/after |
哈哈,别说,这样还真把需要的配置文件找到了。但是,谁看着这个方法,都多少会觉得有点别扭。
现在,我发现了这个可以监视文件系统的任何动作的工具: inotifywait (项目主页) 。
inotifywait 包含在gentoo的 sys-fs/inotify-tools 包里,其他发行版应该也是叫这个名字。
这个工具是使用linux内核的inotify调用,来实现监视功能的。所以你需要有2.6.13以上版本的内核,才会有这个调用。
像上例中,如果要找某个未知文件的该动的话,你可以监视整个$HOME目录,这样:
|
1 |
inotifywait -mr $HOME |
现在你再修改awn的配置,或者打开/修改/删除任何$HOME及其子目录下的文件的话,终端都会显示出来。比如:
|
1 2 3 4 5 6 7 8 9 |
/home/lily/test/ CREATE abcd.txt /home/lily/test/ OPEN abcd.txt /home/lily/test/ ATTRIB abcd.txt /home/lily/test/ CLOSE_WRITE,CLOSE abcd.txt /home/lily/test/ MODIFY abcd.txt /home/lily/test/ OPEN abcd.txt /home/lily/test/ MODIFY abcd.txt /home/lily/test/ CLOSE_WRITE,CLOSE abcd.txt /home/lily/test/ DELETE abcd.txt |
这个就是我在~/test下执行
|
1 |
touch abcd.txt && echo 111 > abcd.txt && rm abcd.txt |
的时候的结果,很详细吧?
另外值得注意的是,如果你 $HOME 下的文件数目比较多,大于 /proc/sys/fs/inotify/max_user_watches 里的值(默认才8k)的话,inotifywait 就会提示超出限制,报错了。这时候你可以估算下总的文件数,然后手工修改上限值。
|
1 |
echo 170000 | sudo tee /proc/sys/fs/inotify/max_user_watches |
我这边把上限改成了170000,发现CPU和内存的占用都还不是很明显,还是完全可以接受的。
PS:除了使用这个inotifywait以外,你也可以在自己的程序里直接调用内核的inotify完成某些特定的功能,而且python和perl都有相应的模块可以直接调了,更详细的介绍可以看这里(翻遍了google,好不容易才找到这原文啊,BS那些转载不注明原地址的,还有转了以后,不管代码格式却分成10来页骗点击量的)。
记录你的终端操作 ── script
不知广大linuxer有没有这样的经历:你要给别人演示一个终端下的操作过程,或者遇到什么难题需要求助别人,想把终端的操作过程(输入)及输出都记录下来。
这时候,如果过程不是很长,一屏以内的话一般可以选择直接截图;如果只是一个命令的输出,可以用重定向将标准输出(和/或 标准错误)直接定向到文件。
但是如果这个过程,既不是很短,比如输入和输出加起来有上万行;又不是一个命令能搞定的,该怎么办呢?将terminal的缓冲区定义地很大,再选择/复制/粘帖显然不是个好办法。
这时候,script就派上用场了,在终端里输入script,表面上只是打印了一行“Script started, file is typescript”的文字,但是其实,现在已经新开了一个session了,从此刻开始,任何你的输入和程序的输出都将被如实地记录到当前目录下的 typescript 文件里,直到你打exit退出这个session。退出以后,你可以用任何文本编辑器打开这个 typescript 文件,不过由于这个文件将所有的ANSI控制符都记录进去了,所以,如果你的PS1有彩色的,或者有执行ls之类的输出彩色信息的命令的时候,直接用文本编辑器看到的输出会有点乱,不过这样的好处是,如果你 cat typescript 的话,所有的颜色都也可以恢复了。另外,如果你想去掉颜色的话,可以执行
|
1 |
cat typescript | sed 's/\x1b[[0-9;]*.//g' > nocolor |
这个命令可以基本把颜色代码去掉。
另外,还有一个办法也可以完成此项工作,就是使用 screen 的时候,加上 -L 参数,会在当然目录生成一个 screenlog.0 的文本文件,同样,这也是一个带ANSI控制符的文本文件,忠实地记录了你的所有操作。
现在,有了终端的详细“截图”,你就可以将得到文件发给对方,进行交流了,哈哈~
《SED单行脚本快速参考》的 awk 实现
sed和awk都是linux下常用的流编辑器,他们各有各的特色,本文并不是要做什么对比,而是权当好玩,把《SED单行脚本快速参考》这文章,用awk做了一遍~
至于孰好孰坏,那真是很难评论了。一般来说,sed的命令会更短小一些,同时也更难读懂;而awk稍微长点,但是if、while这样的,逻辑性比较强,更加像“程序”。到底喜欢用哪个,就让各位看官自己决定吧!
PS: 貌似这个配色,单行的代码多了以后,拖动的时候会有点眼花的感觉,将就下吧,呵呵。
文本间隔:
——–
# 在每一行后面增加一空行
|
1 |
sed G |
|
1 |
awk '{printf("%s\n\n",$0)}' |
# 将原来的所有空行删除并在每一行后面增加一空行。
# 这样在输出的文本中每一行后面将有且只有一空行。
|
1 |
sed '/^$/d;G' |
|
1 |
awk '!/^$/{printf("%s\n\n",$0)}' |
# 在每一行后面增加两行空行
|
1 |
sed 'G;G' |
|
1 |
awk '{printf("%s\n\n\n",$0)}' |
# 将第一个脚本所产生的所有空行删除(即删除所有偶数行)
|
1 |
sed 'n;d' |
|
1 |
awk '{f=!f;if(f)print $0}' |
# 在匹配式样“regex”的行之前插入一空行
|
1 |
sed '/regex/{x;p;x;}' |
|
1 |
awk '{if(/regex/)printf("\n%s\n",$0);else print $0}' |
# 在匹配式样“regex”的行之后插入一空行
|
1 |
sed '/regex/G' |
|
1 |
awk '{if(/regex/)printf("%s\n\n",$0);else print $0}' |
# 在匹配式样“regex”的行之前和之后各插入一空行
|
1 |
sed '/regex/{x;p;x;G;}' |
|
1 |
awk '{if(/regex/)printf("\n%s\n\n",$0);else print $0}' |
编号:
——–
# 为文件中的每一行进行编号(简单的左对齐方式)。这里使用了“制表符”
# (tab,见本文末尾关于’\t’的用法的描述)而不是空格来对齐边缘。
|
1 |
sed = filename | sed 'N;s/\n/\t/' |
|
1 |
awk '{i++;printf("%d\t%s\n",i,$0)}' |
# 对文件中的所有行编号(行号在左,文字右端对齐)。
|
1 |
sed = filename | sed 'N; s/^/ /; s/ *\(.\{6,\}\)\n/\1 /' |
|
1 |
awk '{i++;printf("%6d %s\n",i,$0)}' |
# 对文件中的所有行编号,但只显示非空白行的行号。
|
1 |
sed '/./=' filename | sed '/./N; s/\n/ /' |
|
1 |
awk '{i++;if(!/^$/)printf("%d %s\n",i,$0);else print}' |
# 计算行数 (模拟 “wc -l”)
|
1 |
sed -n '$=' |
|
1 |
awk '{i++}END{print i}' |
文本转换和替代:
——–
# Unix环境:转换DOS的新行符(CR/LF)为Unix格式。
|
1 2 3 |
sed 's/.$//' # 假设所有行以CR/LF结束 sed 's/^M$//' # 在bash/tcsh中,将按Ctrl-M改为按Ctrl-V sed 's/\x0D$//' # ssed、gsed 3.02.80,及更高版本 |
|
1 |
awk '{sub(/\x0D$/,"");print $0}' |
# Unix环境:转换Unix的新行符(LF)为DOS格式。
|
1 2 3 4 |
sed "s/$/`echo -e \\\r`/" # 在ksh下所使用的命令 sed 's/$'"/`echo \\\r`/" # 在bash下所使用的命令 sed "s/$/`echo \\\r`/" # 在zsh下所使用的命令 sed 's/$/\r/' # gsed 3.02.80 及更高版本 |
|
1 |
awk '{printf("%s\r\n",$0)}' |
# DOS环境:转换Unix新行符(LF)为DOS格式。
|
1 2 |
sed "s/$//" # 方法 1 sed -n p # 方法 2 |
|
1 |
DOS环境的略过 |
# DOS环境:转换DOS新行符(CR/LF)为Unix格式。
# 下面的脚本只对UnxUtils sed 4.0.7 及更高版本有效。要识别UnxUtils版本的
# sed可以通过其特有的“–text”选项。你可以使用帮助选项(“–help”)看
# 其中有无一个“–text”项以此来判断所使用的是否是UnxUtils版本。其它DOS
# 版本的的sed则无法进行这一转换。但可以用“tr”来实现这一转换。
|
1 2 |
sed "s/\r//" infile >outfile # UnxUtils sed v4.0.7 或更高版本 tr -d \r <infile >outfile # GNU tr 1.22 或更高版本 |
|
1 |
DOS环境的略过 |
# 将每一行前导的“空白字符”(空格,制表符)删除
# 使之左对齐
|
1 |
sed 's/^[ \t]*//' # 见本文末尾关于'\t'用法的描述 |
|
1 |
awk '{sub(/^[ \t]+/,"");print $0}' |
# 将每一行拖尾的“空白字符”(空格,制表符)删除
|
1 |
sed 's/[ \t]*$//' # 见本文末尾关于'\t'用法的描述 |
|
1 |
awk '{sub(/[ \t]+$/,"");print $0}' |
# 将每一行中的前导和拖尾的空白字符删除
|
1 |
sed 's/^[ \t]*//;s/[ \t]*$//' |
|
1 |
awk '{sub(/^[ \t]+/,"");sub(/[ \t]+$/,"");print $0}' |
# 在每一行开头处插入5个空格(使全文向右移动5个字符的位置)
|
1 |
sed 's/^/ /' |
|
1 |
awk '{printf(" %s\n",$0)}' |
# 以79个字符为宽度,将所有文本右对齐
# 78个字符外加最后的一个空格
|
1 |
sed -e :a -e 's/^.\{1,78\}$/ &/;ta' |
|
1 |
awk '{printf("%79s\n",$0)}' |
# 以79个字符为宽度,使所有文本居中。在方法1中,为了让文本居中每一行的前
# 头和后头都填充了空格。 在方法2中,在居中文本的过程中只在文本的前面填充
# 空格,并且最终这些空格将有一半会被删除。此外每一行的后头并未填充空格。
|
1 2 |
sed -e :a -e 's/^.\{1,77\}$/ & /;ta' # 方法1 sed -e :a -e 's/^.\{1,77\}$/ &/;ta' -e 's/\( *\)\1/\1/' # 方法2 |
|
1 |
awk '{for(i=0;i<39-length($0)/2;i++)printf(" ");printf("%s\n",$0)}' #相当于上面的方法二 |
# 在每一行中查找字串“foo”,并将找到的“foo”替换为“bar”
|
1 2 3 4 5 |
sed 's/foo/bar/' # 只替换每一行中的第一个“foo”字串 sed 's/foo/bar/4' # 只替换每一行中的第四个“foo”字串 sed 's/foo/bar/g' # 将每一行中的所有“foo”都换成“bar” sed 's/\(.*\)foo\(.*foo\)/\1bar\2/' # 替换倒数第二个“foo” sed 's/\(.*\)foo/\1bar/' # 替换最后一个“foo” |
|
1 |
awk '{gsub(/foo/,"bar");print $0}' # 将每一行中的所有“foo”都换成“bar” |
# 只在行中出现字串“baz”的情况下将“foo”替换成“bar”
|
1 |
sed '/baz/s/foo/bar/g' |
|
1 |
awk '{if(/baz/)gsub(/foo/,"bar");print $0}' |
# 将“foo”替换成“bar”,并且只在行中未出现字串“baz”的情况下替换
|
1 |
sed '/baz/!s/foo/bar/g' |
|
1 |
awk '{if(/baz$/)gsub(/foo/,"bar");print $0}' |
# 不管是“scarlet”“ruby”还是“puce”,一律换成“red”
|
1 2 |
sed 's/scarlet/red/g;s/ruby/red/g;s/puce/red/g' #对多数的sed都有效 gsed 's/scarlet\|ruby\|puce/red/g' # 只对GNU sed有效 |
|
1 |
awk '{gsub(/scarlet|ruby|puce/,"red");print $0}' |
# 倒置所有行,第一行成为最后一行,依次类推(模拟“tac”)。
# 由于某些原因,使用下面命令时HHsed v1.5会将文件中的空行删除
|
1 2 |
sed '1!G;h;$!d' # 方法1 sed -n '1!G;h;$p' # 方法2 |
|
1 |
awk '{A[i++]=$0}END{for(j=i-1;j>=0;j--)print A[j]}' |
# 将行中的字符逆序排列,第一个字成为最后一字,……(模拟“rev”)
|
1 |
sed '/\n/!G;s/\(.\)\(.*\n\)/&\2\1/;//D;s/.//' |
|
1 |
awk '{for(i=length($0);i>0;i--)printf("%s",substr($0,i,1));printf("\n")}' |
# 将每两行连接成一行(类似“paste”)
|
1 |
sed '$!N;s/\n/ /' |
|
1 |
awk '{f=!f;if(f)printf("%s",$0);else printf(" %s\n",$0)}' |
# 如果当前行以反斜杠“\”结束,则将下一行并到当前行末尾
# 并去掉原来行尾的反斜杠
|
1 |
sed -e :a -e '/\\$/N; s/\\\n//; ta' |
|
1 |
awk '{if(/\\$/)printf("%s",substr($0,0,length($0)-1));else printf("%s\n",$0)}' |
# 如果当前行以等号开头,将当前行并到上一行末尾
# 并以单个空格代替原来行头的“=”
|
1 |
sed -e :a -e '$!N;s/\n=/ /;ta' -e 'P;D' |
|
1 |
awk '{if(/^=/)printf(" %s",substr($0,2));else printf("%s%s",a,$0);a="\n"}END{printf("\n")}' |
# 为数字字串增加逗号分隔符号,将“1234567”改为“1,234,567”
|
1 2 |
gsed ':a;s/\B[0-9]\{3\}\>/,&/;ta' # GNU sed sed -e :a -e 's/\(.*[0-9]\)\([0-9]\{3\}\)/\1,\2/;ta' # 其他sed |
|
1 2 |
#awk的正则没有后向匹配和引用,搞的比较狼狈,呵呵。 awk '{while(match($0,/[0-9][0-9][0-9][0-9]+/)){$0=sprintf("%s,%s",substr($0,0,RSTART+RLENGTH-4),substr($0,RSTART+RLENGTH-3))}print $0}' |
# 为带有小数点和负号的数值增加逗号分隔符(GNU sed)
|
1 |
gsed -r ':a;s/(^|[^0-9.])([0-9]+)([0-9]{3})/\1\2,\3/g;ta' |
|
1 2 |
#和上例差不多 awk '{while(match($0,/[^\.0-9][0-9][0-9][0-9][0-9]+/)){$0=sprintf("%s,%s",substr($0,0,RSTART+RLENGTH-4),substr($0,RSTART+RLENGTH-3))}print $0}' |
# 在每5行后增加一空白行 (在第5,10,15,20,等行后增加一空白行)
|
1 2 |
gsed '0~5G' # 只对GNU sed有效 sed 'n;n;n;n;G;' # 其他sed |
|
1 |
awk '{print $0;i++;if(i==5){printf("\n");i=0}}' |
选择性地显示特定行:
——–
# 显示文件中的前10行 (模拟“head”的行为)
|
1 |
sed 10q |
|
1 |
awk '{print;if(NR==10)exit}' |
# 显示文件中的第一行 (模拟“head -1”命令)
|
1 |
sed q |
|
1 |
awk '{print;exit}' |
# 显示文件中的最后10行 (模拟“tail”)
|
1 |
sed -e :a -e '$q;N;11,$D;ba' |
|
1 2 |
#用awk干这个有点亏,得全文缓存,对于大文件肯定很慢 awk '{A[NR]=$0}END{for(i=NR-9;i<=NR;i++)print A[i]}' |
# 显示文件中的最后2行(模拟“tail -2”命令)
|
1 |
sed '$!N;$!D' |
|
1 |
awk '{A[NR]=$0}END{for(i=NR-1;i<=NR;i++)print A[i]}' |
# 显示文件中的最后一行(模拟“tail -1”)
|
1 2 |
sed '$!d' # 方法1 sed -n '$p' # 方法2 |
|
1 2 |
#这个比较好办,只存最后一行了。 awk '{A=$0}END{print A}' |
# 显示文件中的倒数第二行
|
1 2 3 |
sed -e '$!{h;d;}' -e x # 当文件中只有一行时,输出空行 sed -e '1{$q;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,显示该行 sed -e '1{$d;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,不输出 |
|
1 2 |
#存两行呗(当文件中只有一行时,输出空行) awk '{B=A;A=$0}END{print B}' |
# 只显示匹配正则表达式的行(模拟“grep”)
|
1 2 |
sed -n '/regexp/p' # 方法1 sed '/regexp/!d' # 方法2 |
|
1 |
awk '/regexp/{print}' |
# 只显示“不”匹配正则表达式的行(模拟“grep -v”)
|
1 2 |
sed -n '/regexp/!p' # 方法1,与前面的命令相对应 sed '/regexp/d' # 方法2,类似的语法 |
|
1 |
awk '!/regexp/{print}' |
# 查找“regexp”并将匹配行的上一行显示出来,但并不显示匹配行
|
1 |
sed -n '/regexp/{g;1!p;};h' |
|
1 |
awk '/regexp/{print A}{A=$0}' |
# 查找“regexp”并将匹配行的下一行显示出来,但并不显示匹配行
|
1 |
sed -n '/regexp/{n;p;}' |
|
1 |
awk '{if(A)print;A=0}/regexp/{A=1}' |
# 显示包含“regexp”的行及其前后行,并在第一行之前加上“regexp”所在行的行号 (类似“grep -A1 -B1”)
|
1 |
sed -n -e '/regexp/{=;x;1!p;g;$!N;p;D;}' -e h |
|
1 |
awk '{if(F)print;F=0}/regexp/{print NR;print b;print;F=1}{b=$0}' |
# 显示包含“AAA”、“BBB”和“CCC”的行(任意次序)
|
1 |
sed '/AAA/!d; /BBB/!d; /CCC/!d' # 字串的次序不影响结果 |
|
1 |
awk '{if(match($0,/AAA/) && match($0,/BBB/) && match($0,/CCC/))print}' |
# 显示包含“AAA”、“BBB”和“CCC”的行(固定次序)
|
1 |
sed '/AAA.*BBB.*CCC/!d' |
|
1 |
awk '{if(match($0,/AAA.*BBB.*CCC/))print}' |
# 显示包含“AAA”“BBB”或“CCC”的行 (模拟“egrep”)
|
1 2 |
sed -e '/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d # 多数sed gsed '/AAA\|BBB\|CCC/!d' # 对GNU sed有效 |
|
1 2 |
awk '/AAA/{print;next}/BBB/{print;next}/CCC/{print}' awk '/AAA|BBB|CCC/{print}' |
# 显示包含“AAA”的段落 (段落间以空行分隔)
# HHsed v1.5 必须在“x;”后加入“G;”,接下来的3个脚本都是这样
|
1 |
sed -e '/./{H;$!d;}' -e 'x;/AAA/!d;' |
|
1 2 |
awk 'BEGIN{RS=""}/AAA/{print}' awk -vRS= '/AAA/{print}' |
# 显示包含“AAA”“BBB”和“CCC”三个字串的段落 (任意次序)
|
1 |
sed -e '/./{H;$!d;}' -e 'x;/AAA/!d;/BBB/!d;/CCC/!d' |
|
1 |
awk -vRS= '{if(match($0,/AAA/) && match($0,/BBB/) && match($0,/CCC/))print}' |
# 显示包含“AAA”、“BBB”、“CCC”三者中任一字串的段落 (任意次序)
|
1 2 |
sed -e '/./{H;$!d;}' -e 'x;/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d gsed '/./{H;$!d;};x;/AAA\|BBB\|CCC/b;d' # 只对GNU sed有效 |
|
1 |
awk -vRS= '/AAA|BBB|CCC/{print "";print}' |
# 显示包含65个或以上字符的行
|
1 |
sed -n '/^.\{65\}/p' |
|
1 |
cat ll.txt | awk '{if(length($0)>=65)print}' |
# 显示包含65个以下字符的行
|
1 2 |
sed -n '/^.\{65\}/!p' # 方法1,与上面的脚本相对应 sed '/^.\{65\}/d' # 方法2,更简便一点的方法 |
|
1 |
awk '{if(length($0)<=65)print}' |
# 显示部分文本——从包含正则表达式的行开始到最后一行结束
|
1 |
sed -n '/regexp/,$p' |
|
1 |
awk '/regexp/{F=1}{if(F)print}' |
# 显示部分文本——指定行号范围(从第8至第12行,含8和12行)
|
1 2 |
sed -n '8,12p' # 方法1 sed '8,12!d' # 方法2 |
|
1 |
awk '{if(NR>=8 && NR<12)print}' |
# 显示第52行
|
1 2 3 |
sed -n '52p' # 方法1 sed '52!d' # 方法2 sed '52q;d' # 方法3, 处理大文件时更有效率 |
|
1 |
awk '{if(NR==52){print;exit}}' |
# 从第3行开始,每7行显示一次
|
1 2 |
gsed -n '3~7p' # 只对GNU sed有效 sed -n '3,${p;n;n;n;n;n;n;}' # 其他sed |
|
1 |
awk '{if(NR==3)F=1}{if(F){i++;if(i%7==1)print}}' |
# 显示两个正则表达式之间的文本(包含)
|
1 |
sed -n '/Iowa/,/Montana/p' # 区分大小写方式 |
|
1 |
awk '/Iowa/{F=1}{if(F)print}/Montana/{F=0}' |
选择性地删除特定行:
——–
# 显示通篇文档,除了两个正则表达式之间的内容
|
1 |
sed '/Iowa/,/Montana/d' |
|
1 |
awk '/Iowa/{F=1}{if(!F)print}/Montana/{F=0}' |
# 删除文件中相邻的重复行(模拟“uniq”)
# 只保留重复行中的第一行,其他行删除
|
1 |
sed '$!N; /^\(.*\)\n\1$/!P; D' |
|
1 |
awk '{if($0!=B)print;B=$0}' |
# 删除文件中的重复行,不管有无相邻。注意hold space所能支持的缓存大小,或者使用GNU sed。
|
1 |
sed -n 'G; s/\n/&&/; /^\([ -~]*\n\).*\n\1/d; s/\n//; h; P' #bones7456注:我这里此命令并不能正常工作 |
|
1 |
awk '{if(!($0 in B))print;B[$0]=1}' |
# 删除除重复行外的所有行(模拟“uniq -d”)
|
1 |
sed '$!N; s/^\(.*\)\n\1$/\1/; t; D' |
|
1 |
awk '{if($0==B && $0!=l){print;l=$0}B=$0}' |
# 删除文件中开头的10行
|
1 |
sed '1,10d' |
|
1 |
awk '{if(NR>10)print}' |
# 删除文件中的最后一行
|
1 |
sed '$d' |
|
1 2 |
#awk在过程中并不知道文件一共有几行,所以只能通篇缓存,大文件可能不适合,下面两个也一样 awk '{B[NR]=$0}END{for(i=0;i<=NR-1;i++)print B[i]}' |
# 删除文件中的最后两行
|
1 |
sed 'N;$!P;$!D;$d' |
|
1 |
awk '{B[NR]=$0}END{for(i=0;i<=NR-2;i++)print B[i]}' |
# 删除文件中的最后10行
|
1 2 |
sed -e :a -e '$d;N;2,10ba' -e 'P;D' # 方法1 sed -n -e :a -e '1,10!{P;N;D;};N;ba' # 方法2 |
|
1 |
awk '{B[NR]=$0}END{for(i=0;i<=NR-10;i++)print B[i]}' |
# 删除8的倍数行
|
1 2 |
gsed '0~8d' # 只对GNU sed有效 sed 'n;n;n;n;n;n;n;d;' # 其他sed |
|
1 |
awk '{if(NR%8!=0)print}' |head |
# 删除匹配式样的行
|
1 |
sed '/pattern/d' # 删除含pattern的行。当然pattern可以换成任何有效的正则表达式 |
|
1 |
awk '{if(!match($0,/pattern/))print}' |
# 删除文件中的所有空行(与“grep ‘.’ ”效果相同)
|
1 2 |
sed '/^$/d' # 方法1 sed '/./!d' # 方法2 |
|
1 |
awk '{if(!match($0,/^$/))print}' |
# 只保留多个相邻空行的第一行。并且删除文件顶部和尾部的空行。
# (模拟“cat -s”)
|
1 2 |
sed '/./,/^$/!d' #方法1,删除文件顶部的空行,允许尾部保留一空行 sed '/^$/N;/\n$/D' #方法2,允许顶部保留一空行,尾部不留空行 |
|
1 |
awk '{if(!match($0,/^$/)){print;F=1}else{if(F)print;F=0}}' #同上面的方法2 |
# 只保留多个相邻空行的前两行。
|
1 |
sed '/^$/N;/\n$/N;//D' |
|
1 |
awk '{if(!match($0,/^$/)){print;F=0}else{if(F<2)print;F++}}' |
# 删除文件顶部的所有空行
|
1 |
sed '/./,$!d' |
|
1 |
awk '{if(F || !match($0,/^$/)){print;F=1}}' |
# 删除文件尾部的所有空行
|
1 2 |
sed -e :a -e '/^\n*$/{$d;N;ba' -e '}' # 对所有sed有效 sed -e :a -e '/^\n*$/N;/\n$/ba' # 同上,但只对 gsed 3.02.*有效 |
|
1 |
awk '/^.+$/{for(i=l;i<NR-1;i++)print "";print;l=NR}' |
# 删除每个段落的最后一行
|
1 |
sed -n '/^$/{p;h;};/./{x;/./p;}' |
|
1 2 |
#很长,很ugly,应该有更好的办法 awk -vRS= '{B=$0;l=0;f=1;while(match(B,/\n/)>0){print substr(B,l,RSTART-l-f);l=RSTART;sub(/\n/,"",B);f=0};print ""}' |
特殊应用:
——–
# 移除手册页(man page)中的nroff标记。在Unix System V或bash shell下使
# 用’echo’命令时可能需要加上 -e 选项。
|
1 2 3 |
sed "s/.`echo \\\b`//g" # 外层的双括号是必须的(Unix环境) sed 's/.^H//g' # 在bash或tcsh中, 按 Ctrl-V 再按 Ctrl-H sed 's/.\x08//g' # sed 1.5,GNU sed,ssed所使用的十六进制的表示方法 |
|
1 |
awk '{gsub(/.\x08/,"",$0);print}' |
# 提取新闻组或 e-mail 的邮件头
|
1 |
sed '/^$/q' # 删除第一行空行后的所有内容 |
|
1 |
awk '{print}/^$/{exit}' |
# 提取新闻组或 e-mail 的正文部分
|
1 |
sed '1,/^$/d' # 删除第一行空行之前的所有内容 |
|
1 |
awk '{if(F)print}/^$/{F=1}' |
# 从邮件头提取“Subject”(标题栏字段),并移除开头的“Subject:”字样
|
1 |
sed '/^Subject: */!d; s///;q' |
|
1 |
awk '/^Subject:.*/{print substr($0,10)}/^$/{exit}' |
# 从邮件头获得回复地址
|
1 |
sed '/^Reply-To:/q; /^From:/h; /./d;g;q' |
|
1 2 |
#好像是输出第一个Reply-To:开头的行?From是干啥用的?不清楚规则。。 awk '/^Reply-To:.*/{print;exit}/^$/{exit}' |
# 获取邮件地址。在上一个脚本所产生的那一行邮件头的基础上进一步的将非电邮地址的部分剃除。(见上一脚本)
|
1 |
sed 's/ *(.*)//; s/>.*//; s/.*[:<] *//' |
|
1 2 |
#取尖括号里的东西吧? awk -F'[<>]+' '{print $2}' |
# 在每一行开头加上一个尖括号和空格(引用信息)
|
1 |
sed 's/^/> /' |
|
1 |
awk '{print "> " $0}' |
# 将每一行开头处的尖括号和空格删除(解除引用)
|
1 |
sed 's/^> //' |
|
1 |
awk '/^> /{print substr($0,3)}' |
# 移除大部分的HTML标签(包括跨行标签)
|
1 |
sed -e :a -e 's/<[^>]*>//g;/</N;//ba' |
|
1 |
awk '{gsub(/<[^>]*>/,"",$0);print}' |
# 将分成多卷的uuencode文件解码。移除文件头信息,只保留uuencode编码部分。
# 文件必须以特定顺序传给sed。下面第一种版本的脚本可以直接在命令行下输入;
# 第二种版本则可以放入一个带执行权限的shell脚本中。(由Rahul Dhesi的一
# 个脚本修改而来。)
|
1 2 |
sed '/^end/,/^begin/d' file1 file2 ... fileX | uudecode # vers. 1 sed '/^end/,/^begin/d' "$@" | uudecode # vers. 2 |
|
1 2 |
#我不想装个uudecode验证,大致写个吧 awk '/^end/{F=0}{if(F)print}/^begin/{F=1}' file1 file2 ... fileX |
# 将文件中的段落以字母顺序排序。段落间以(一行或多行)空行分隔。GNU sed使用
# 字元“\v”来表示垂直制表符,这里用它来作为换行符的占位符——当然你也可以
# 用其他未在文件中使用的字符来代替它。
|
1 2 |
sed '/./{H;d;};x;s/\n/={NL}=/g' file | sort | sed '1s/={NL}=//;s/={NL}=/\n/g' gsed '/./{H;d};x;y/\n/\v/' file | sort | sed '1s/\v//;y/\v/\n/' |
|
1 |
awk -vRS= '{gsub(/\n/,"\v",$0);print}' ll.txt | sort | awk '{gsub(/\v/,"\n",$0);print;print ""}' |
# 分别压缩每个.TXT文件,压缩后删除原来的文件并将压缩后的.ZIP文件
# 命名为与原来相同的名字(只是扩展名不同)。(DOS环境:“dir /b”
# 显示不带路径的文件名)。
|
1 2 |
echo @echo off >zipup.bat dir /b *.txt | sed "s/^\(.*\)\.TXT/pkzip -mo \1 \1.TXT/" >>zipup.bat |
|
1 |
DOS环境再次略过,而且我觉得这里用bash的参数 ${i%.TXT}.zip 替换更帅。 |
下面的一些SED说明略过,需要的朋友自行查看原文。
python程序打包工具 ── cx_Freeze
cx_Freeze是一个类似py2exe的工具,它们区别是py2exe是将python程序打包成windows下可以执行的exe文件的,而cx_Freeze则是将python程序打包为linux下可以直接执行的ELF格式的二进制可执行文件(看说明好像也能生成windows的可执行文件,号称跨平台)。
cx_Freeze的作用就是让你的python程序可以脱离python运行环境,在没有安装python的微型linux系统(例如cdlinux、tinycore等)里,方便地运行你的python程序。从功能上来说,也可以将其理解为一个python程序的编译器,将你的源码隐藏起来。
使用方法也很简单,下载以后,解压,如一般的python模块一样,cd到目录以后,
|
1 |
python setup.py install |
就可以完成安装,这样你的系统里就会有cxfreeze命令了。
然后,cd到你的python程序的目录执行
|
1 |
cxfreeze 你的程序文件.py --target-dir dist |
就会在当然目录生成一个dist的目录,里面就会有一堆so文件和可执行目标文件了,当然如果你还有图片或者其他数据文件的话,手工复制到相应目录,这时候运行那个可执行文件,就应该能看到效果了。
现在只需将dist目录打包,传到没有python的目标系统里,你程序也就能运行了。
PS: cx_Freeze还有另外两种使用方法,需要了解的话,可以自行查看随代码打包的html文档。