分类: '精华' 的归档
Notchy 1.3.7
上次写 Notchy 的时候(从接手到日用:我把 Notchy 改成了什么样),我自以为已经比较完善了,自己想要的功能都有了。但后面自己深度使用以后,包括也有网友反馈,发现还是有不少细节需要打磨。
于是一晃一个半月过去,翻了下 git log,从 1.2.7 到 1.3.7,中间又是 23 个 commit、小一千五百行 Swift,版本号跳了整整十个小版本。。。
趁着 1.3.7 刚发出去,把这段时间攒的东西整理一下:
标签页:从”能用”到”顺手”
上次提到的 Shadow Tab(右键一个 Xcode 或 Pinned 标签页,开一个 cd 到同目录但不启动 agent 的纯 shell)用顺手之后,发现每次都要right-click 选菜单有点烦,于是加了个 Cmd+Shift+T,直接对当前标签页开一个分身。Pin、unpin、开 Shadow Tab 的时候,标签页角上也会弹一个小图标提示一下,不然经常按完不确定到底生效没有。
关掉当前标签页这件事之前也有点反人类:永远跳到”下一个”,跟浏览器的习惯不一样。现在改成关掉后自动回到关之前那个活跃的标签页,一路往回找,符合直觉多了。
标签页多了之后,顺序调整和快速定位就成了刚需。这次加了两个东西:
一是拖拽排序——按住标签页左右拖,松手自动补位,Cmd+1…9 的跳转序号也跟着重新编号,不用再手动数第几个。
二是 Cmd+K 快速切换器:弹出一个按最近使用顺序排列、支持模糊搜索的会话列表,方向键选、回车跳、Esc 取消。做这个的时候踩了个 AppKit 的老坑——SwiftUI 的浮层(QuickSwitcherOverlay)从视图树里移除之后,并不会自动把键盘焦点还给原来的终端,得在 Esc 或选中之后手动调用 makeFirstResponder 把焦点抢回来,否则切换器关了,键盘输入却发不出去,你会以为是终端卡住了。
终端里能像正经终端一样用了
早些版本的终端体验偏”能跑就行”,这轮补了不少 iTerm2 用户会想念的东西。
右键菜单是最直观的一个:复制/粘贴/全选、查词典、拿选中内容或光标下的词去搜网页、打开光标下的 URL、在 Finder 里显示当前工作目录(或复制路径)、清屏。标签页右键菜单也顺带加了”创建检查点”。
深压(force click)一个单词会弹出系统词典释义,跟 Safari 里的 Look Up 一模一样——原理是接进了 trackpad 的 deep-click 二段位移,从 SwiftTerm 的缓冲区里解出光标下的词,再丢给 AppKit 的 showDefinition(for:at:)。
Cmd+点击打开文件/链接这块改动最细,也最容易在细节上翻车。之前直接点会遇到带空格的路径识别不出来、相对路径解析错目录之类的问题。现在带引号的路径(比如截图文件名里常见的空格)能整体识别成一个链接,相对路径按 shell 当前实际所在目录解析(用 proc_pidinfo 拿真实 cwd,不是猜的),像 agent 输出里常见的 Sources/File.swift:12 这种”文件:行号”引用,点一下直接在 Xcode 里跳到对应行。
另外一个不算起眼但天天受益的:流式输出的时候终端选区不再被冲掉了。原来 SwiftTerm 只要收到新数据就会重置鼠标上报状态,顺带清掉你刚选中的文本;现在只有 vim、htop 这类真正需要鼠标事件的 TUI 才会保留上报,普通 agent 输出流不会再打断你复制粘贴。
输入法这次是另一个坑
上次那篇讲的输入法问题,是 SwiftTerm 的 NSTextInputClient 吞掉预编辑文本(打拼音看不到候选字下面自己打了啥);这次修的是另一层——输入法来源(源)在标签页之间的记忆。
现在每个标签页会记住自己上次用的输入法:一个跑着 CLAUDE.md 项目、习惯打中文的标签页,切走切回来还是中文;旁边一个 Shadow Tab 默认停在英文,互不干扰。且只有 Notchy 面板真正拿到焦点时才会去改系统输入法,不会误动其他 App 正在用的输入法。
这个功能刚上的时候有个隐蔽 bug:macOS 的 panelDidResignKey 有时候一次失焦会触发两次,第二次触发时外部输入法已经被恢复了,结果把”外面那个 App 的中文输入法”错记成了这个标签页的输入法,污染了原本该是英文的 Shadow Tab。加了个 idempotent 保护(guard isPanelKey)才算收住。
同一批还加了 Quick Input:自己绑快捷键到预设命令,按一下自动敲进当前聚焦的终端(内置了 Cmd+G → git status),要不要自动回车可以按行配置,在 Settings → Quick Input 里随便增删,也可以整体关掉。
边边角角的细节
一些不太会单独写文章但用起来很舒服的小改动:
Xcode 工程在磁盘上被挪了地方之后,对应标签页现在会自动刷新到新路径——之前是按项目名字匹配的,工程一挪,标签页就一直 cd 到一个不存在的旧目录。
拖动窗口或者用 Cmd +/-/0 缩放字体的时候,HUD 提示会顺带把终端的字符行列数也标出来:
|
1 |
720 × 400 (120×40) |
外接显示器没接的时候,相关开关会自动置灰并给提示,接上拔下都会跟着实时更新,不用再对着一个点了没反应的开关发呆。
还有个不起眼但对 agent 体验有直接影响的:内嵌终端之前没有正确设置 TERM_PROGRAM,claude 这类会识别宿主终端类型的 CLI 只能退回去看原始的 $TERM 值,现在能正确认出自己是跑在 Notchy 里。
顺手修的一堆 bug
这段时间里还有几个纯粹的显示 bug,挑重点提一句:设置窗口以前是 floating 层级,会盖住其他 App 窗口,改成 normal 就好了;改字体大小之后终端字符被滚动条挡住的问题修了;终端往上滚看历史的时候,敲的字没有正确回显到屏幕上的问题也修了——这几个都是 SwiftTerm 底层渲染逻辑的坑,改动细节没什么好展开的,能用就完事了。
—
十个版本攒下来,Notchy 离”能用”更远了一步,离”顺手”近了一大截。想试试的话去 GitHub 下最新的 DMG 或 ZIP。
每日一辨 DailyDiff
最近上架了一个新 App:DailyDiff(每日一辨)。做它的初衷很简单:一是我自己想把英语再往上提一提,二是儿子也在学英语,我想给他(也给自己)找一个每天花几分钟、细水长流的练法。
市面上背单词的软件很多,但它们解决的基本都是”认识”:看见 soldier 知道是战士,看见 warrior 也知道是战士。可这两个词的区别是什么、什么场合该用哪个——这种”掌握”层面的功夫,几乎没有软件管。而”认识一个单词”和”掌握一个单词”之间恰恰隔着一条鸿沟,它决定了你的英语是只能读,还是真的能用。所以我做了一个专门练这个的 App。
每天一道题,它长什么样
玩法抄了 Wordle 的作业:每天全球所有人拿到同一道题——一对容易混淆的英语近义词,各配一张黑白线稿插图。你用英语写出这两个词在含义、语气、用法上的区别,一两句话就行,然后 AI 给你批改。
批改是这个 App 的核心。不是给个分就完事,而是从五个维度(准确性、覆盖度、语言、清晰度、洞察)各打一个 0–100 的分,每个维度都附一句针对你这次答案的点评——指出你答到位的地方、漏掉的要点,像一对一外教改作业。五个分数汇总成总分和等级,从 D 到 SSS。SSS 很难拿:不光要总分 95 以上,还要求最低的那个维度也不低于 90,纯靠某一项拉平均分是蒙不到的。
批改完揭晓标准答案,对照着学。之后就是熟悉的套路:每日连击打卡、日历一格格点亮,还能导出一张成绩卡分享——卡上只有词对、插图、等级和雷达图,刻意不含答案,朋友看到照样能去玩。
题库目前 200 道,四百张插图全是 AI 生成的黑白线稿,风格统一得像一个插画师画的。
技术上几个有意思的决定
作为技术博客,还是得聊聊后端。整个服务端就是一个 Cloudflare Worker,配 D1(题库和用户数据)和 R2(插图),没有一台服务器要运维,账单基本可以忽略——独立开发选这套栈真的省心。
我之前的服务,都是部署在自己的home lab上的,这也是一次全套采用cloudflare的技术方案,发觉这个赛博菩萨果然名不虚传,免费额度够用不说,wrangler的开发体验还非常棒!
几个细节自认为做得还算讲究:
1. 评分标准(rubric)永远不下发到客户端。客户端只上传题目 ID 和你写的答案,评分要点由服务端按 ID 查表后喂给模型。否则抓个包就能看到得分点,这游戏就没法玩了。
2. 总分和等级不信任模型自己报的数。LLM 的算术是出了名的不可靠,让它算五个维度的加权和,隔三差五给你算错一个。所以模型只负责逐维度打分和写点评,加总、定级在代码里重算。
3. 匿名用户不用注册就能玩,每天免费批改一次。防滥用靠的不是强制登录,而是 Apple 的 App Attest——让苹果证明请求来自真机上的正版 App,机器人和脚本过不来。这套东西的原理和服务端验证的坑,我之前单独写过一篇《Apple App Attest 简介》,感兴趣可以看看。
4. 批改额度是”先预扣、失败退还”。最早的实现是先只读检查额度、批改成功了再扣,看起来很稳妥——但批改一次要跑上一两分钟,这个窗口里并发发请求,每个请求检查时都显示”还有额度”,就都放行了,白烧 token。改成预扣制之后,靠 D1 单写者的串行化保证并发下最多放行额度上限那么多个请求,批改失败再把额度退回去。
免费与收费
说说钱的事,明码标价:每天的题目永远免费,匿名一天能批改 1 次,登录后 2 次。Pro 订阅(月付或年付)解锁 200 道历史题库、研读模式(先看标准答案再作答)和每天 15 次批改。订阅收入拿去付 AI 推理的账单——每一次批改都是真金白银的 API 调用,所以免费额度给得抠门,请理解哈哈。
来玩
App Store 搜「DailyDiff」或「每日一辨」,或者直接点这个链接。中英文界面都有,今天的题不用注册就能做。
如果你试了之后觉得 AI 批改哪次明显不靠谱,或者有任何建议,欢迎邮件 support@dailydiff.vip 或者直接在下面留言——独立开发,每一条反馈我都会看。
顺便说一句,今天的题你打算拿几分?我至今没拿到过自己 App 里的 SSS。
就此,完毕。
从接手到日用:我把 Notchy 改成了什么样
还记得上次那篇吗?当时我接手 Notchy 的时候,基本就是原作者 Adam Lyttle 的初始版本——点子非常好,但功能比较基础,bug 也不少。我本来只是想”修修 bug,打个包”就完事了。
结果一改就停不下来了。
55 个 commit、4600 多行 Swift 之后(当然大部分都是 vibing 的),Notchy 已经从一个”能用”的 demo 变成了我日常干活的主力终端。是的,之前我还是混着状态,现在 iTerm2 已经从 Dock 上消失了。
这篇就来聊聊,到底改了些啥,才让我有底气做出这个切换。
Terminal UX:从”能打字”到”能干活”
原版的终端体验非常朴素——打开一个黑框,能输入命令,仅此而已。要把它当日用终端,差的东西太多了。
动画和视觉:面板从菜单栏后面滑出来(slide-down),背景是 NSVisualEffectView 的毛玻璃效果。看起来比较像一个系统原生组件,而不是一个第三方窗口硬贴在那里。
快捷键:这是最影响手感的部分。
- 全局热键
Ctrl+`呼出/收起面板,任何应用中随时可用 Cmd+1..9切 tab,Cmd+W关 tab,Ctrl+Tab和Ctrl+Shift+Tab循环切换Cmd++/Cmd+-缩放字体(全局生效,持久化),Cmd+0重置Shift+Enter发送换行而不是提交(通过 kitty CSI u 协议实现),这对 Claude Code 的多行输入至关重要Cmd+Backspace清行(发 Ctrl-U)- Copy-on-selection,选中即复制,iTerm2 用户的肌肉记忆
滚动:这块踩了不少坑。原版在 TUI 应用(比如 Claude Code 自己的界面)里滚动完全不工作。修了 alternate screen buffer 的滚轮转发,修了自动跟随输出的逻辑(在底部时跟随新输出,在回看历史时保持位置不动),还修了退出 vim/less 之后视口跳到顶部的 bug——这个 bug 的原因是 alt buffer 的 yDisp 始终是 0,退出时被误判为”用户在回看滚动历史”。Scrollback buffer 大小也做成了可配置的(默认 1000 行,最大 50000)。
字体:支持 Nerd Font,Powerline 图标正常显示。
从 Claude 专属到多 Agent 支持
原版 Notchy 是纯粹为 Claude Code 设计的——检测到 CLAUDE.md 就自动启动 claude,写死的,没有别的选项。
但现实是,越来越多人在用不同的 AI coding agent。OpenAI 的 Codex 出来之后,我公司也给我们同时配备了Claude 和 Codex,我会在不同项目中用不同的agent,Notchy应该能做到自动判断:
- 项目里有
CLAUDE.md→ 启动claude - 项目里有
AGENTS.md→ 启动codex - 两个都有 → 看 Settings 里的 Preferred Agent 设置来决定
- 两个都没有 → 不启动,给你一个普通 shell
终端状态检测也做了相应适配。原版只认 Claude 的输出模式(大写的 Esc to interrupt、Esc to cancel 等),Codex 的输出格式不一样——小写的 esc to cancel、you approved … to run …、Conversation interrupted。现在都能正确识别,notch 上的状态指示对两个 agent 都能工作。
这个改动的价值在于:Notchy 不再是一个”Claude Code 的前端”,而是一个通用的 AI coding agent 终端。以后再出新的 agent,加个 case 就行。
Tab 管理:三种 Tab,各司其职
原版只有 Xcode 自动检测的 tab。我加了一套完整的 tab 类型系统:
- Xcode tab(青色边框):自动创建,跟 Xcode 项目生命周期绑定
- Pinned tab(橙色边框):手动固定的 tab,跨重启持久化。固定时会通过
proc_pidinfo快照当前 shell 的 CWD,重启后自动cd回去并重新检测 AI agent,适用于非 Xcode 的项目。 - Normal tab(无边框):
+按钮创建的临时 tab,关掉 app 就没了
另外加了 Shadow Tab——右键一个 Xcode 或 Pinned tab,选 Shadow Tab,会在旁边开一个 plain shell,cd 到同一个目录但不启动 Claude/Codex。跑 git status、npm run build 这种临时命令特别方便,不用打断正在工作的 agent。名字后面会加个 $ 后缀以示区分。
关 Pinned 和 Xcode tab 之前会弹确认框,防止手滑。这些 tab 带着恢复状态,误关了成本很高。
IME 输入法支持
SwiftTerm 的 NSTextInputClient 实现有问题,输入法的 marked text(预编辑文本)直接被吞掉了。打拼音的时候只能看到候选窗,看不到自己输入了什么。
第一版我做了一个 HUD 风格的浮动面板,显示在光标上方。后来改成了 inline 渲染,和 macOS Terminal.app 的行为一致——用终端前景色画文字,背景色填充遮住底下的块状光标。视觉上自然多了。
这个功能对中文用户来说是刚需。
自动更新 (Sparkle)
手动下载更新太烦了,用户也不会主动去看 GitHub Releases。所以集成了 Sparkle——macOS 上事实标准的自动更新框架。
这块的详细过程我单独写了一篇:给 macOS App 加自动更新:Sparkle 入门。大家可以参考这里。
CI/CD 发布流水线
推一个 v* tag 到 GitHub,Actions 自动搞定剩下的事:
xcodebuild archive构建并用 Developer ID Application 签名notarytool提交公证(Apple 审查恶意代码)- 打包成 DMG 和 ZIP
- 用 EdDSA 私钥签名 ZIP,生成
appcast.xml - 把所有产物挂到 GitHub Release 上
如意要长期维护这个应用,这些都是必不可少的基础设施了。
其他细节
- 外接显示器支持:接了外接显示器(比如 Studio Display)的时候,鼠标悬停在外屏顶部中央(摄像头区域)也能唤出面板,和 MacBook notch 的交互保持一致
- 通话静音:检测到麦克风在使用(Zoom、FaceTime 等),自动把 Notchy 的提示音静音,不会在开会的时候突然”叮”一声
- Checkpoint 增强:加了一个 popover 列出所有 checkpoint,可以浏览、恢复、删除任意一个,不再只能操作最近的那个
- Settings 窗口:从一个简单的菜单 toggle 变成了完整的 Settings 窗口(
Cmd+,),分 General / Integrations / About 三个 tab - Notch 动画优化:改成更平滑的 ease-in-out 曲线,修了 notch 和屏幕顶部之间的缝隙,修了 hover → click 模式切换时 notch 缩小的问题
- 面板大小持久化:拖动调整大小后会记住,下次打开恢复。调整时右上角还会显示尺寸指示
为什么能替代 iTerm2
这个问题的答案很简单:我日常用终端 90% 的场景是跑 AI coding agent。
在这个场景下,Notchy 比 iTerm2 好用。Ctrl+` 一按就出来,不用切窗口;Xcode 项目自动检测,不用手动 cd;agent 自动启动,不用手动输命令;状态一目了然,notch 上的小药丸告诉你 agent 是在干活还是在等你。
剩下 10% 的临时命令?Shadow Tab 搞定。
当然,如果你的主要场景是 SSH 管理十几台服务器、或者需要 tmux 分屏,iTerm2 仍然是更好的选择。但如果你和我一样,日常就是在本地项目里跑 Claude Code 或 Codex——试试 Notchy 吧。
GitHub: bones7456/notchy,非常欢迎提issue、MR等。。。
安装方式:去 Releases 下载 DMG 或 zip,拖进 /Applications 就行。因为签名、公证过,所以不会弹 Gatekeeper 警告。
全文完。
Claude Code Account Switcher
如今这AI时代,如果你也写写代码,我相信你肯定在用一些AI工具了吧?
如果你恰好用的也是Claude code,那大概率也会因为每月20$的pro套餐用量不够而烦恼吧?这时,如果你不差钱,可能就直接订阅200$的max套餐了,但如果你也觉得200刀有点下不去手,那可能再买一个20刀,就是更加可以接受的方案了。
此时,你就会遇到两个Claude账号频繁切换的问题了。。。那你可能就需要这个小工具了。
功能挺简单的,也无需我过多介绍了,直接看图就能明白了。这是一个macOS下的菜单栏小工具。可以同时登录多个Claude账号,能查看每个账号的余量,能帮你快速切换账号。
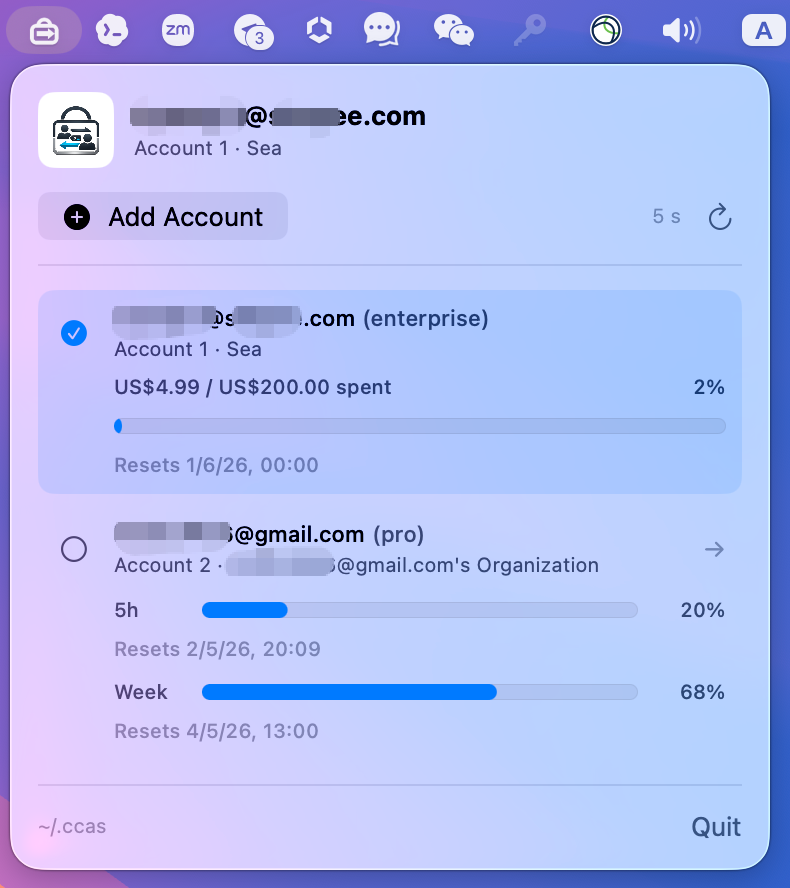
截图里,我的账号1是公司给开的enterprise账号,一个月200$的token(也是不经用的);账号2是我自己的pro账号。两种账号都是支持的。
工具以MIT开源。代码在GitHub。等我再整理一下,放个编译好的二进制吧。
App Store Small Business Program
事情是这样的,3月初的时候,我上线了我的第一款收费APP(用于在睡眠期间监测和记录呼噜声的),然后陆陆续续也有几笔成交了。
于是我这个数据控,就研究了一下Apple的开发者后台,里面的一些看板和详细数据。由于我的APP一共也才成交了几笔而已,样本非常有限,还刻意和资深开发者朋友 TualatriX 聊了一下,还真让我发现了一些门道和问题。。。
那就是在app store connect里,Sales、Proceeds的数据,和你给APP的定价肯定都会不一样。原因有以下几层:
第一层,是汇率的影响。
因为你的 APP 是全球卖的。用户可能用的是欧元、日元、人民币付款,而你后台的结算通常是按美元(或你本地货币)来算的。中间一定会经历一次甚至两次货币转换。
关键点在于:Apple 用的不是实时汇率,而是自己的一套定价和结算汇率(按周期更新)。这就会带来几个结果:
- 同样标价 2.99,在不同国家对应的本地价格其实是不一样的
- 不同货币换算回来的“基准金额”,本身就有偏差
- 即使同一个国家,汇率调整周期不同,Proceeds 也可能轻微波动
换句话说,从一开始,你的“2.99”,在全球范围内就已经不是一个严格一致的数字了。
然后,才是第二层:税。
App Store 的价格是“含税展示价”,不同国家税率不同(比如 VAT、GST)。这些税是从用户支付的钱里先扣掉的。
接着是第三层:Apple 抽成。
而且这个抽成,是在“去税之后”的金额上算的(默认抽走30%)。再剩下的才是你真正拿到的 Proceeds。
所以完整链路其实是:本地定价 → 汇率换算 → 扣税 → Apple 抽成 → 最终收入(Proceeds)
那,作为开发者,有什么可以action的东西么?
显然,汇率和税,作为小卡拉米的我们,是没法去影响的,但苹果其实有个“App Store Small Business Program”,是可以给小开发者一些抽成上的优惠的。
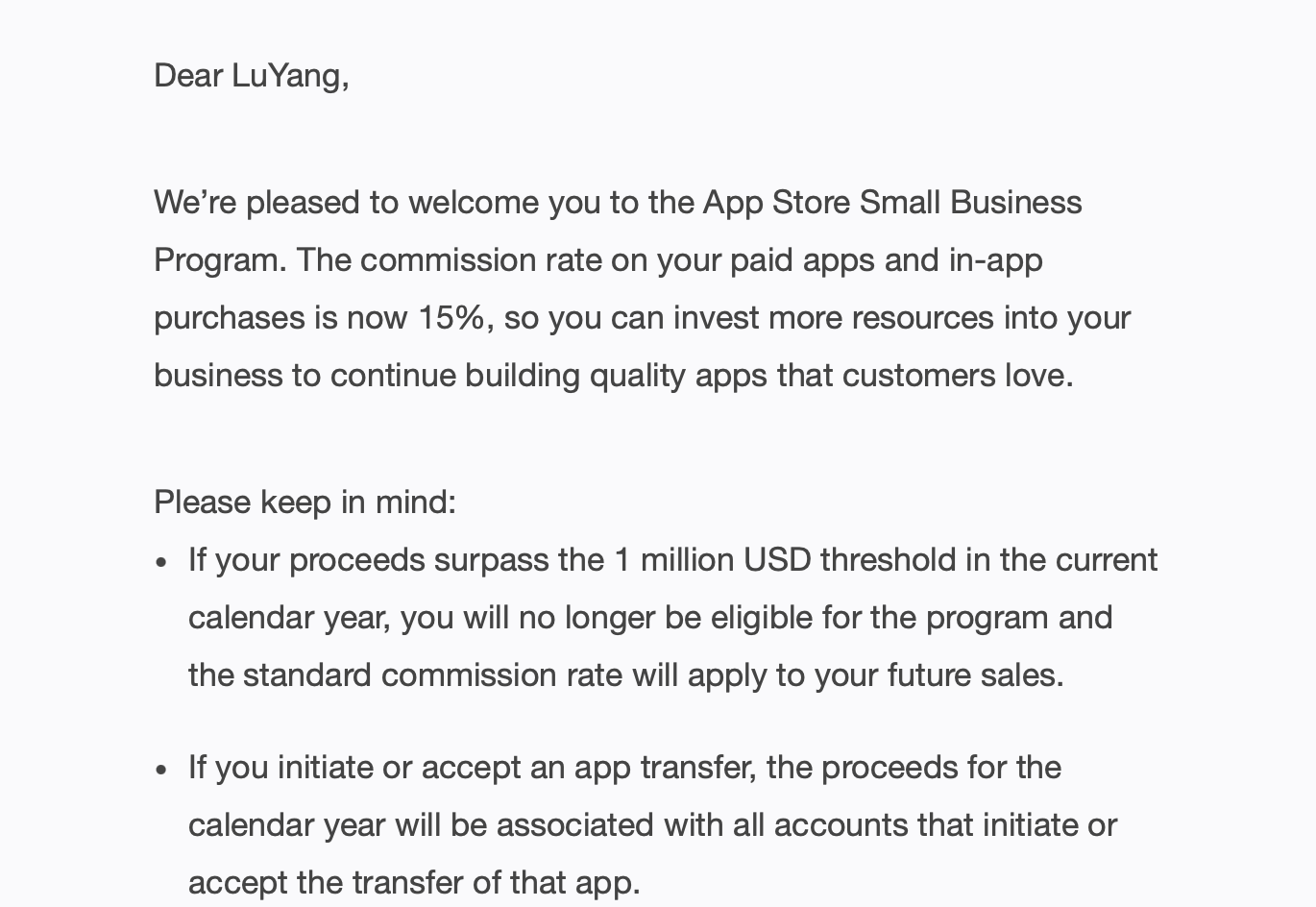
具体来说,苹果针对年销售额不足1百万美元的小开发者,可以把默认的30%的抽成比例,降到15%。其实之前我也听说过这个计划,但当时也没细看,以为是默认开通的。但其实是要开发者去单独申请,并审核开通的。方法倒是很简单,就是用开发者账号登录后,在这个页面点“Enroll now”,填上相应的信息,就算提交成功了。
注意,提交成功,并不代表你enroll成功了,在收到以下邮件之前,抽成将还是30%。而且苹果处理这个请求相当地慢,以我为例花了3周的时间,而且我中间还催过一次。
好了,最后祝所有开发者都能APP大卖!早日被踢出Small Business Program!
新加坡天气云图
在新加坡呆过的同学就会知道,这地方的天气变化莫测,尤其最近这段时间,属于新加坡的雨季,就更夸张了。一天能经历N次下雨、晴天、下雨的过程。
而且虽然新加坡就那么点儿大,但由于地形差异、对流性降雨、城市热岛效应等因素的影响,经常是过了一个街区,天气就完全不同了。
因此,在这地方看天级的甚至小时级的天气预报是肯定不够的。很多人出门前都会打开新加坡气象局的网站(PC|手机)去看降雨云图,往往就能比较准确地判断接下来的天气走向了。
这个网站其实并不提供天气“预报”,它只会告诉你,最近2个小时内,降雨带的走势是怎么样的。只告诉你事实,让你自己来预测未来。这点很好。
但,依然有两个不足之处:
第一,它不会在地图上显示“你所在的位置”,即使他的Mobile页面会请求用户的地理位置信息,但并不会显示;虽然你肯定知道你自己大致在哪里,但判断就不够精确了。
第二,它只能查看2小时内的天气,不能查看历史。
然后,我看了下这个网站请求的数据,还挺简单的。于是就自己糊了一个更纯粹的天气网站,尽量适配了PC和手机端,补上用户位置,更重要的是补上查看历史的功能(目前能查看2025年11月往后的任何时间)。
链接在这里,默认和官方一样是看最近2个小时数据,点击右边的📅图标,可以激活“历史模式”,就可以查看一整天的数据了,希望用得开心。
点击查看全文 »
thirsty@SG
前言:
自从我2022年来到新加坡以后,就发现这边有些地方确实是挺人性化的。举个我自己感受最深的例子:这边会有很多的免费喝水点,分布在机场里、食阁角落、公厕边上、小区内部,最主要还有很多在公园里和绿道边。要知道新加坡是一个接近赤道的热带国家,气温一直比较高,如果出门在外,是很容易口干舌燥的,如果去哪都要自己带水会很麻烦,如果光靠买水,那经济上的压力也会不小。
在户外能喝到免费放心的饮用水,对喜欢户外跑步或者徒步的人(比如我)尤其友好。但也因此带来了一个小小的问题:当我探索到一个陌生的地方,我要怎么才能知道附近哪来有喝水点呢?
试着解决:
我当然想过在google maps或者苹果的地图里搜索,但很遗憾,这个数据可能只在新加坡有意义,需求也相对比较小众,因此这些巨头企业是覆盖不到这个需求的。在新加坡的各种政府网站,我也没有搜到想要的答案。
而且,我看到有人做了类似事情,比如这个: https://linktr.ee/brayontng 作者是一个大一到学生,用Google forms收集数据,最终在google maps的自定义地图上做展示。但现在似乎也有大半年没更新了,而且我身边熟知的几个点好些都没有收录。还有就是大部分点都没有图片,真要用起来可能也不是太方便。
我的方案:
所以,我想到做一个手机app,嵌入地图SDK,打开app就能显示附近的喝水点,除了告诉你经纬度以外,还会告诉你所在楼层、水是常温的还是冰水或者热水;并且能显示一张图片,让你大致知道周边的情况,还能方便地调用第三方地图软件导航过去。
当然,我自己并没有完整的数据。所以,还会有一个“上传喝水点”的功能,希望发挥广大网友的力量,逐步完善这个数据。最终希望能覆盖整个新加坡绝大部分的喝水点。
于是,就有了 thirsty@SG。不过由于我也是刚学的SwiftUI,对界面设计也不太在行,因此目前app可能会有这样那样的小问题,界面也比较简陋,但我还是会尽我所能把这个事情做好。
APP:
所以,大家可以通过这里下载这个叫做“thirsty@SG”的app。目前只有iOS的,因为我不会安卓的app开发,可能暂时不会有安卓的版本。而且目前仅限在新加坡范围内使用,暂时没有打算支持更多地区。
关于上传喝水点:
方法也很简单,点击app左下角,会弹出上传的界面,此时需要拍一张喝水点的照片,app会自动获取此时的经纬度信息,填上一些必要的信息以后,就可以点界面上的“upload”上传了。
显示上传成功以后,暂时还不会直接在app上显示,为了防止有人滥用而误导其他用户,我设计了数据需要审核才能生效,审核我主要会看上传的照片,因此照片是不接受图库里选择的,只能现场拍,望大家理解。我也会尽快审核,慢也不太会超过一天。
上传的时候,可以选择填上你的邮箱。即使填了,也不会在任何地方公开这个信息,万一以后有会员体系什么的,这些做过贡献的用户,肯定默认就是高级用户。(对,我在画饼了,哈哈)
如果在使用app的过程中有任何问题,可以通过X(前Twitter)联系我: https://twitter.com/senob_ 其他未尽事宜,也欢迎联系咨询。