开源的命令行OCR软件──tesseract
tesseract-ocr是一个跨平台开源的OCR软件(Optical Character Recognition,光学字符识别),它历史悠久,早期是HP实验室的项目,现托管于google code。
大部分常用的linux发行版,应该都在源里包含了此软件,所以ubuntu下只需要 sudo apt-get install tesseract-ocr tesseract-ocr-eng 就可以安装了,注意必须安装 tesseract-ocr-eng 这个是识别英文字符所必须的数据文件。而在gentoo下,也只需要 emerge app-text/tesseract 就可以了,但是也必须给这个包添加 linguas_en 这个use,才会安装所需要的数据文件。
关于数据文件,还得交代一下,其实tesseract在2.0版以后,已经有了学习能力了,如果你想提高某个字体的识别率,或者识别不在默认语言包里的UTF-8字符(比如中文)的话,可以安装这个方法来训练出自己的数据文件。
这个OCR软件能干嘛呢?典型地应用就是识别验证码,哈哈。所以以这个为例,来介绍一下使用方法,先来看看这几个验证码(可“图片另存为”,然后自行测试):
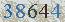

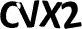
这几个都是用默认的数据文件能正确识别的例子,由于tesseract只识别tiff格式的图片文件,所以识别之前,需要将图片先转成tif格式,具体如下:
|
1 2 3 4 5 |
$ convert cnblogs.com.jpe ppm:- | ppm2tiff yzm.tif $ tesseract yzm.tif out Tesseract Open Source OCR Engine $ cat out.txt 1750 |
同时,也有些比较难的验证码,是程序不能正确识别的,如下几个就是例子:
虽然识别的正确性不是非常高,但是已经很不错了,哈哈。
PS: 有没有人训练个识别google验证码专用的数据文件?
shellex 在 2009年12月29日 22:03 说:【 】
很好。。。方便了这下
Tweets that mention I am LAZY bones ? : 开源的命令行OCR软件──tesseract -- Topsy.com 在 2009年12月29日 22:04 说:【 】
[…] This post was mentioned on Twitter by shellex and 骨头, topsy_top20k. topsy_top20k said: li2z新文章: 开源的命令行OCR软件──tesseract (http://cli.gs/0LTEb) […]
ggarlic 在 2009年12月29日 22:06 说:【 】
而在ubuntu下,也只需要 emerge app-text/tesseract 就可以了。。。。。。。。。。
bones7456 在 2009年12月30日 08:36 说:【 】
呃。。写错了,哈哈~~
xiooli 在 2009年12月30日 00:09 说:【 】
额,我前不久还写了个生成验证码图片的脚本呢,不过是生成数学算式的,要算出答案才算验证过关。
bones7456 在 2009年12月30日 08:37 说:【 】
能把算式识别出来的话,要答案有啥难的?
xiooli 在 2009年12月30日 11:41 说:【 】
额,我要用汉字写呢?
bones7456 在 2009年12月30日 12:21 说:【 】
要自己训练一个数据文件啊,呵呵,用你那生成验证码的程序,搞出所有汉字的图片给它认,估计马上就能学会了。
xiooli 在 2009年12月31日 11:38 说:【 】
额,这个玩意能学习就太无敌了,估计我用篆字写都能给认出来~~
shuge.lee 在 2009年12月30日 02:39 说:【 】
骨头坏,净教小孩做坏事去
OCR不是这么用的,人家是拿来做文献数字化的……
bones7456 在 2009年12月30日 08:38 说:【 】
呃。。确实,不过文献数字化不太好讨论嘛~这个方便,所以以此为例喽,哈哈~~
volans 在 2009年12月30日 10:27 说:【 】
OCR还是挺好玩儿的,破解验证码也很好玩儿,但现在的验证码难度越来越大了……
去年还玩儿过这个游戏……
_http://journeyboy.blog.sohu.com/104513800.html
推荐一个外国人收集的验证码网站:
http://caca.zoy.org/wiki/PWNtcha
abettor 在 2009年12月30日 13:56 说:【 】
邪恶啊!
我的口水都流下来了~~~
这事不能说太细!
marklemon 在 2010年02月04日 14:06 说:【 】
请问 好像没有现成的中文语言库下载哦
bones7456 在 2010年02月04日 22:34 说:【 】
没找过哦,不知道中文的识别率会怎么样。
sam 在 2010年03月01日 16:36 说:【 】
你好,我在debian 5.0下试了很奇怪,无法识别出来。
$ wget http://li2z.cn/data/yzm/cnblogs.com.jpe
$ convert cnblogs.com.jpe ppm:- | ppm2tiff yzm.tif
$ tesseract yzm.tif out
Tesseract Open Source OCR Engine
$ cat out.txt
;;:g;;gg:搂;;;gg:搂:g;;;g:搂:i;;g
我看了一下软件包的版本是:
$ ls -l /var/cache/apt/archives/tesseract-ocr*
-rw-r–r– 1 root root 837710 2008-06-13 05:32 /var/cache/apt/archives/tesseract-ocr_2.03-2_i386.deb
-rw-r–r– 1 root root 1374982 2007-11-12 13:26 /var/cache/apt/archives/tesseract-ocr-deu_2.00-1_all.deb
-rw-r–r– 1 root root 1014242 2007-11-12 13:26 /var/cache/apt/archives/tesseract-ocr-eng_2.00-1_all.deb
请问是哪儿设置有问题?
bones7456 在 2010年03月01日 16:41 说:【 】
其他的几个图片也都不能识别吗?多试几个好了。
另外,deu的是什么语言的数据包?删了好了。。。
python验证码识别之Discuz(二) | Observer专栏杂记 在 2010年03月07日 07:17 说:【 】
[…] 承接上文,上文写道去噪,本文应该接着从切块开始写,然后到比对的。然则上文写完之后开始收集训练样本,把样本用去噪算法一做,惨不忍睹;再加上上文之后有很多人留言提了不少意见,所以有了新的方向。
首先骨头兄提议说可以用tesseract来做OCR,这个确实是一个很好的建议。很多验证码其实很简单,根本用不到高级的东东,直接用tesseract就可以摆平。然而经过实验,效果不尽如人意,如图:还有关于选取多角度多采样的建议,后来发现会导致样本容量太大,性能受到影响,所以也作出了一定的调整,目前来说验证码识别的部分算是写完了,绝对识别率在10%左右,如果可接受其他候选结果的话,识别率在50%左右,不能识别的主要因素是去噪效果不理想和没有成功切块。最后还有关于Discuz验证码使用反色阴影的建议,虽然可能可以大幅提高去噪成功率,但是因为不够通用被我舍弃了。 ` 我不喜欢直接写结论,我会把我的探索过程和绕圈子过程一起写出来,因为这样看了才有收获,否则也就是”又一个注册码破解器”这种东东而已,能写出来多少就写多少吧。 […]黑传说 在 2010年05月17日 12:35 说:【 】
这个识别大文件如何?我想把大批的扫描版pdf转化为文字版。
bones7456 在 2010年05月17日 12:50 说:【 】
这就很难说了,估计一般吧~
用 Tesseract OCR 系统扫描中文 : 自娱者 在 2010年12月16日 19:47 说:【 】
[…] 总得来说,tesseract 对中文的支持还有待加强,特别是对繁体而言(当然也可能是我测试的图片质量问题影响,不过相比简体而言确实有待提高)。tesseract 当然不只有应用于文字扫描,还有一些更好玩的应用,比如,图片识别码的扫描。这里有一篇介绍图片识别码的文章:开源的命令行OCR软件–tesseract 。 […]