2009年 12月 29日 的归档
开源的命令行OCR软件──tesseract
tesseract-ocr是一个跨平台开源的OCR软件(Optical Character Recognition,光学字符识别),它历史悠久,早期是HP实验室的项目,现托管于google code。
大部分常用的linux发行版,应该都在源里包含了此软件,所以ubuntu下只需要 sudo apt-get install tesseract-ocr tesseract-ocr-eng 就可以安装了,注意必须安装 tesseract-ocr-eng 这个是识别英文字符所必须的数据文件。而在gentoo下,也只需要 emerge app-text/tesseract 就可以了,但是也必须给这个包添加 linguas_en 这个use,才会安装所需要的数据文件。
关于数据文件,还得交代一下,其实tesseract在2.0版以后,已经有了学习能力了,如果你想提高某个字体的识别率,或者识别不在默认语言包里的UTF-8字符(比如中文)的话,可以安装这个方法来训练出自己的数据文件。
这个OCR软件能干嘛呢?典型地应用就是识别验证码,哈哈。所以以这个为例,来介绍一下使用方法,先来看看这几个验证码(可“图片另存为”,然后自行测试):
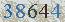

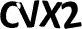
这几个都是用默认的数据文件能正确识别的例子,由于tesseract只识别tiff格式的图片文件,所以识别之前,需要将图片先转成tif格式,具体如下:
|
1 2 3 4 5 |
$ convert cnblogs.com.jpe ppm:- | ppm2tiff yzm.tif $ tesseract yzm.tif out Tesseract Open Source OCR Engine $ cat out.txt 1750 |
同时,也有些比较难的验证码,是程序不能正确识别的,如下几个就是例子:
虽然识别的正确性不是非常高,但是已经很不错了,哈哈。
PS: 有没有人训练个识别google验证码专用的数据文件?