今天看到@pengjiayou发的一个网站速度测试的链接,觉得挺好玩的,于是我也申请了一个,呵呵。
这个方法不同于之前的这个测试方法,这次是让别人帮你测试你的网站速度,并能把结果汇总、统计,这样的好处是可以了解全国各地(好像没有统计国外的访问量)的人,打开你的网站会是什么样的速度,而不只是你自己打开的速度。
方法就是在监控宝免费注册一个用户,然后在你站上放一个10k左右的图片,将几个必要的信息填在监控宝的后台,就可以了。你可以手工把链接发给别人让人家帮你测试,也可以在你的网站上放置一段js代码,这样所有访客访问你的网站都会产生一条监控记录。我目前用的是后者,也就是说,如果你现在是用浏览器打开这文章在看的话,你的这次访问,就已经帮我生成了一条记录了,哈哈。
监控宝的UI做得也是很赞的,可以把监控结果清晰地呈现出来,如下是我站速度情况,数据还不是很多,好多省都还是空白状态,呵呵。
图中也可以看到大陆的网速和香港比,还是有较大差距的,唉,万恶的资本主义!

另外,监控宝除了可以监控访问速度以外,还可以监控网站的可用率、服务器状态(需要snmp)、服务的状态等;不仅会给你email日报,还可以购买短信告警提醒。如果你也是站长的话,也是可以考虑的哦。
发表于:2010年02月02日 22:59 | 分类: 网站收集 | 7 个评论 »
贴一些这两天我和老婆在三亚游玩的照片,图片均可点击放大。
欢迎评论,哈哈。
点击查看全文 »
发表于:2010年01月27日 23:00 | 分类: 流水帐 | 26 个评论 »
最近,也快有半个月没有更新博客了,为了证明我还存在于这个网络世界里,也得出来冒个泡了。
那到底这半个月我干嘛去了呢?其实,最近我请了婚假,一来是要完成老家的喜酒;二来是为了好好休息休息,度个蜜月。
所以,从1.14开始,我就回到老家了,发现老家在短短半年的时间里,已经变了一个样子了:屋顶盖上瓦了、外墙贴上瓷砖了、围墙重新做过了、墙也重新刷了一遍、大大小小的门也都基本上换掉了。不过,和房子一起变化的还有我爸妈的面容,变得更憔悴了,头上的白发也明显了不少,看得出这段时间他们的辛苦劳作,真的要谢谢他们。
老家的婚宴是在1.16,农历腊月初二,话说这个日子貌似挺好,只在我村里就还有好几对也是这个日子办酒。当天天气也算不错,虽然没有很大的阳光,但是温度不低,老婆穿起婚纱也不觉得非常冷,算是老天给的好礼了吧。这天,很多亲朋好友都来了,大家也都比较尽兴。
接下来几天,我带着老丈人等几人,把我老家附近好玩的地方都转了一圈,每天也跑得比较累,所以,虽然家里也有宽带和wifi,但是也没啥心思上网了,即使上来,也只是东看看西看看,没有静下心来写点东西,呵呵。
然后,到了昨天,就开始了我们的蜜月旅行:昨天早上还在老家,中午赶到杭州,直接去了机场,傍晚就飞到了三亚,真快。发现这边好热好舒服啊,感觉和浙江的夏末秋初的天气差不多(当然,没那么闷),中午大概能到30度,早晚稍微凉快些,空气质量很不错,潮潮的,总觉得有海的气息。
今天,去了一趟天涯海角,感觉还是不错的,捡捡贝壳,在沙滩上随便走走,都觉得很惬意。哦,对了,还发现这边的很多贝壳里面,都有寄居蟹,哈哈,很好玩哦,各种各样不一样的贝壳里,都可能有同一种寄居蟹呢。
明天去哪玩还没想好,恩,为了明天能更有精力,得早点睡了,哈哈。
发表于:2010年01月26日 23:06 | 分类: 流水帐 | 11 个评论 »
本文是我看了可能吧的诱导性虚假下载链接不完全评测的一些感想,是写给windows用户的,linuxer请自觉忽略,呵呵。
下面通过一个表格来对比windows和linux的软件安装过程:
| linux |
windows |
sudo apt-get install XXX
或者
sudo emerge XXX |
搜索:
打开baidu(也许部分是用谷歌的,估计马上也没得用了)?输入XXX,挨个找,找到XX软件站 |
下载:
或许,你已经通过搜索找到了一个软件下载站了,现在,你点开这个站,就会发生诱导性虚假下载链接不完全评测所描述的一幕,你必须凭借你多年的上网经验(说上网经验是好听的,其实就是就是被骗的经验),分辨真假。 |
安装:
也许你一不小心就下到病毒了,哦,可能你买了杀毒软件,一扫描,确认无毒。就开始安装了,然后安装过程中的每一步(一般都有很多个“下一步”吧?)你都得小心了,因为可能会有安装XX工具栏的选项隐藏在安装界面,默认勾着,需要你点掉呢。还有其他的陷阱不一一叙述。 |
| 最后,也许你历尽千辛万苦,终于装好了,一打开,却发现是XXX汉化版,试用n天,请输入注册码;或者干脆在使用过程中弹出广告。 |
呵呵,写着写着,发现自己不是写这类评论文章的料,还是算了。不过,本来也不算什么评论,只是我看了那文章的一点点感想而已,希望不要有太多的口水。
发表于:2010年01月13日 21:59 | 分类: 流水帐 | 29 个评论 »
今天,我给大家介绍两款自动化的网盘下载工具,用于自动下载Megaupload、Rapidshare等网盘的文件。
首先是有图形界面的FreeRapid,这是采用java编写的,所以可以跨平台使用,而且有比较良好的图形界面和多语言支持,改下设置,就可以出来中文界面,所以使用非常方便,也很容易上手,适合普通用户使用。
而且,FreeRapid还有个好处是支持的网盘网站非常的多,国外的大大小小的网盘站点几乎都能搞定。对各网站的支持还是以插件的形式出现的,也就是说,即使你的网盘站点的下载方式有变化,或者有新的网盘站点出现,FreeRapid也能很轻松地升级,以适应这个变化。事实上,在使用FreeRapid的过程中,也确实经常会看到有插件要更新的。
好了,大致说完了FreeRapid,这个的优点,刚说了,就是易用,因为有GUI嘛,不过,某些时候这样正是它的缺点所在(哲学中,矛盾性的普遍性得到了很好的验证,哈哈。),如果我的机器没有X怎么办呢?呵呵,不用着急,我们还有Plowshare。
Plowshare已经默认包含在了gentoo或者arch的官方源里了,可以直接emerge或者yaourt,但是ubuntu源里,却还未包含,所以使用ubuntu的朋友需要自己下载deb包或者源码进行安装了。
这个的Plowshare比起FreeRapid来,支持的站点稍微少些,不过人家是bash脚本,不用拖个jre也不用X,还是很不错的,而且,它不止支持下载,其实还是支持上传的,哈。
使用起来也不烦,一般情况下只需要
就好了,更详细的使用说明──比如支持某些站点的用户名、密码之类的──可以看官方说明。
再说一句,这个也是模块化支持多站点的哦,而且作者还提供API,鼓励大家都去写模块呢。
怎么样,方便吧?
发表于:2010年01月11日 00:46 | 分类: CLI软件, GUI软件 | 10 个评论 »
今天,吼吼来找我说,他的硬盘,有个分区一共有234G,但是只用了222G,就报满了,无法继续使用了。
其实这个问题,我不久前刚看过一下,只要你仔细看 mkfs.ext3 的man page,就可以知道原因了,其中有这么一句:
|
|
-m reserved-blocks-percentage Specify the percentage of the filesystem blocks reserved for the super-user. This avoids fragmentation, and allows root-owned daemons, such as syslogd(8), to continue to function correctly after non-privileged processes are prevented from writing to the filesystem. The default percentage is 5%. |
也就是说,ext文件系统,包括ext2、ext3、ext4都会默认预留5%的磁盘空间,留给root用户维护系统或者记录系统关键日志的时候使用,这也就是导致普通用户无法使用部分磁盘空间的原因了。
我个人觉得,这个选项用在根分区或者/var之类的分区,还是有一定的必要性的。但是如果是/home、/opt或者干脆是/data之类的数据分区,就显得有点多此一举了。而且,现在的磁盘空间越来越大,5%往往会有10多G,都可以存一部高清了。这么多空间浪费了,是不是太可惜了呢?
于是,就去找相关资料,看能可否在不格式化的情况下改变保留区块的大小。
吼吼找到了这个,比我想像得还要简单,甚至都不需要umount分区,就可以进行修改。
具体操作过程如下,已经加了详细注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#之前的保留区有 732463 块 lily@LLY:~$ sudo tune2fs -l /dev/sda7 | grep "Reserved block count" Reserved block count: 732463 #已用空间+可用空间 和 总空间 相比,还少了近3个G lily@LLY:~$ df 文件系统 1K-块 已用 可用 已用% 挂载点 /dev/sda7 57677500 47662588 7085060 88% /home #调整: lily@LLY:~$ sudo tune2fs -r 25600 /dev/sda7 tune2fs 1.41.9 (22-Aug-2009) Setting reserved blocks count to 25600 #再来看看空间,哈哈 lily@LLY:~$ df 文件系统 1K-块 已用 可用 已用% 挂载点 /dev/sda7 57677500 47662584 9912516 83% /home #确认调整成功 lily@LLY:~$ sudo tune2fs -l /dev/sda7 | grep "Reserved block count" Reserved block count: 25600 |
看到了吧?就一眨眼的功夫,我就多了3G多的空间,哈哈。而且我还不是直接完全去掉保留区块呢,也留了百多兆以防不时之需呢,呵呵。
算了一下,吼吼那个3.4T的磁盘阵列,省出来的空间居然比我的整个硬盘都大。嗨。。。
发表于:2010年01月08日 20:19 | 分类: 经验技巧 | 13 个评论 »
为了说明这个问题,先来看下这个简单的C程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#include <stdio.h> #include <stdarg.h> void writeLogInfo(const char *sFormat, ...){ char sOutBuffer[4196]; va_list lvalist; va_start(lvalist, sFormat); vsnprintf(sOutBuffer, sizeof(sOutBuffer)-2, sFormat, lvalist); va_end(lvalist); printf("log: %s\n", sOutBuffer); } int main(){ writeLogInfo("int=%s", 123); return 0; } |
这程序用gcc编译,即使是用 -Wall 打开所有的警告,也是不会有任何报错的。
但是执行结果是什么呢?由于 writeLogInfo 的是一个参数里指定的是 %s ,而第二个参数确是整型数字 123。所以程序义无反顾地出现了“段错误”而崩溃掉。这种问题在项目代码超过万行以后,要debug起来,也是会浪费很多时间的。
有的人会发现,如果把main里的writeLogInfo直接换成printf,那么在编译的时候,gcc会报一个警告:“警告:格式‘%s’需要类型‘char *’,但实参 2 的类型为‘int’”(Gcc4.x默认就会报,Gcc3.x要加 -Wall 选项才报),如果我们自己的定义的writeLogInfo函数也能有这个警告,那么这种bug将在编译的时候就可以完美解决了。
那么具体怎么实现呢?先来看下面这段代码,功能是和上面的完全一样的,连错误都一样,呵呵:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include <stdio.h> #include <stdarg.h> #ifndef __GNUC__ # define __attribute__(x) /*NOTHING*/ #endif void writeLogInfo(const char *sFormat, ...){ char sOutBuffer[4196]; va_list lvalist; va_start(lvalist, sFormat); vsnprintf(sOutBuffer, sizeof(sOutBuffer)-2, sFormat, lvalist); va_end(lvalist); printf("log: %s\n", sOutBuffer); } void writeLogInfo(const char *sFormat, ...) __attribute__((format(printf,1,2))); int main(){ writeLogInfo("int=%s", 123); return 0; } |
当你尝试用gcc编译这个文件的时候,你就可以看到警告了,哈哈。
可以看到,这里的关键就是“__attribute__((format(printf,1,2)))” ,这句话的作用就是告诉编译器,前面这个函数呢,参数类型是类似printf的,格式化字符串在参数的第1个位置,扩展参数从第2个位置开始,然后编译器就明白了~
然后,上面的4~6行呢,是为了兼容非Gcc的编译器而加的,这样其他的编译器就会直接无视整个 __attribute__ 了,这样至少不会报错。
其实,这个检查格式化字串的功能(format),只是“函数属性”的一个而已,另外还有许多有用又有意思的属性,比如函数的别名啊(alias),是否已经过时啊(deprecated),等等~要了解这些用法的话,建议去看看官方文档。
发表于:2010年01月04日 17:32 | 分类: 编程相关 | 16 个评论 »
昨天,我喝醉了。
直到现在,才基本缓过神来,所以,起来写点东西纪念一下。
昨天是我大喜的日子,请了大学、高中同学们喝我的喜酒,对了,还有网友代表TualatriX也来了。虽然规模不是很大,但是,觉得大家的气氛都蛮好的。非常感谢所有到场的人。
其实,在酒店里,我还没怎么醉,但是后来大伙又提议去K歌,于是,在包厢里,唱了几首歌,又喝了几瓶,就彻底醉了。
呃,觉得脑子还不是很清醒,再睡一觉再说,哈哈。
发表于:2010年01月03日 14:15 | 分类: 流水帐 | 31 个评论 »
本文为nginx 禁止某个 User_Agent 的方法的姊妹篇,不知所云的话,建议先看看这文。
由于之前已经将某个特别疯狂的迅雷的User_Agent给封掉了,所以最近一段时间,我的那源服务器也运行地比较稳定,但是今天,Linux Deepin 9.12正式发布了,由于我给Deepin做了一个iso的镜像,所以服务器又经历了一个访问高峰,如下图:

从这里也可以看出Linux Deepin的受欢迎程度,哈哈。
可以看到从11:00以后,100M的带宽就已经被完全撑满了。。。一看日志,大部分又是迅雷干的,但这次迅雷不是用某个特定的UA来访问了,而是各有变化,但是却都包含MSIE,哈哈。
当然IE用户直接访问的话,也会有这个MSIE,但是没办法,为了保全Ubuntu APT-HTTP的合法权益,只能限制一下MSIE了。
但是怎么限制呢?总不能人家用MSIE的连主页面都打不开吧?哈哈,最好的办法就是限速,于是,有了这个配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
server { listen 80; server_name ubuntu.srt.cn; access_log /var/log/nginx/mirror.access.log; location / { root /data/mirrors; autoindex on; index index.html index.htm; if ($http_user_agent ~ "MSIE") { limit_rate 2k; } if ($http_user_agent ~ "Mozilla/4.0\ \(compatible;\ MSIE\ 6.0;\ Windows\ NT\ 5.1;\ SV1;\ .NET\ CLR\ 1.1.4322;\ .NET\ CLR\ 2.0.50727\)") { return 404; } } error_page 500 502 503 504 /50x.html; location = /50x.html { root /var/www/nginx-default; } } |
让我们邪恶的看一下效果,哈哈:
wget的默认UA的时候:
|
|
$ wget --no-cache http://u.srt.cn/ubuntu/ls-lR.gz -O /dev/null --14:08:28-- http://u.srt.cn/ubuntu/ls-lR.gz => `/dev/null' 正在解析主机 u.srt.cn... 211.155.227.167 Connecting to u.srt.cn|211.155.227.167|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:8,051,367 (7.7M) [text/plain] 100%[====================================>] 8,051,367 6.34M/s 14:08:29 (6.33 MB/s) - `/dev/null' saved [8051367/8051367] |
UA里含有MSIE的时候:
|
|
$ wget --no-cache --user-agent="Something with MSIE; bla bla" http://u.srt.cn/ubuntu/ls-lR.gz -O /dev/null --14:07:59-- http://u.srt.cn/ubuntu/ls-lR.gz => `/dev/null' 正在解析主机 u.srt.cn... 211.155.227.167 Connecting to u.srt.cn|211.155.227.167|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:8,051,367 (7.7M) [text/plain] 0% [ ] 49,152 2.08K/s ETA 1:02:38 |
某个该死的特定UA:
|
|
$ wget --no-cache --user-agent="Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)" http://u.srt.cn/ubuntu/ls-lR.gz -O /dev/null --14:09:22-- http://u.srt.cn/ubuntu/ls-lR.gz => `/dev/null' 正在解析主机 u.srt.cn... 211.155.227.167 Connecting to u.srt.cn|211.155.227.167|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 404 Not Found 14:09:22 错误 404:Not Found。 |
从上图也可以看到,做了这个设置以后,从14:00左右开始,服务器的流量虽然还是比较大,但是已经趋于正常了。
所以,偶尔要从我源里下东西的同学,可以用firefox直接下载,也可以用axel或者wget之类的工具下,但是千万别用IE相关的工具,不然,后果自负,哈哈~
发表于:2009年12月30日 16:52 | 分类: 经验技巧 | 15 个评论 »
tesseract-ocr是一个跨平台开源的OCR软件(Optical Character Recognition,光学字符识别),它历史悠久,早期是HP实验室的项目,现托管于google code。
大部分常用的linux发行版,应该都在源里包含了此软件,所以ubuntu下只需要 sudo apt-get install tesseract-ocr tesseract-ocr-eng 就可以安装了,注意必须安装 tesseract-ocr-eng 这个是识别英文字符所必须的数据文件。而在gentoo下,也只需要 emerge app-text/tesseract 就可以了,但是也必须给这个包添加 linguas_en 这个use,才会安装所需要的数据文件。
关于数据文件,还得交代一下,其实tesseract在2.0版以后,已经有了学习能力了,如果你想提高某个字体的识别率,或者识别不在默认语言包里的UTF-8字符(比如中文)的话,可以安装这个方法来训练出自己的数据文件。
这个OCR软件能干嘛呢?典型地应用就是识别验证码,哈哈。所以以这个为例,来介绍一下使用方法,先来看看这几个验证码(可“图片另存为”,然后自行测试):

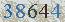

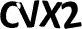
这几个都是用默认的数据文件能正确识别的例子,由于tesseract只识别tiff格式的图片文件,所以识别之前,需要将图片先转成tif格式,具体如下:
|
|
$ convert cnblogs.com.jpe ppm:- | ppm2tiff yzm.tif $ tesseract yzm.tif out Tesseract Open Source OCR Engine $ cat out.txt 1750 |
同时,也有些比较难的验证码,是程序不能正确识别的,如下几个就是例子:



虽然识别的正确性不是非常高,但是已经很不错了,哈哈。
PS: 有没有人训练个识别google验证码专用的数据文件?
发表于:2009年12月29日 22:01 | 分类: CLI软件 | 21 个评论 »
