试试OpenClaw
这次南美之行,去了半个月,发现AI圈又有了一些新的变化。有只龙虾,从ClawBot改名成了OpenClaw,似乎挺火的。。。
回来也有几天了,想跟上大家的步伐,于是也决定尝试一下。
安装的体验倒是非常好,按着官网来,给配上大模型的key(我用的是anthropic/claude-sonnet-4-5)、链接WhatsApp、开一些skills,就能用了。。
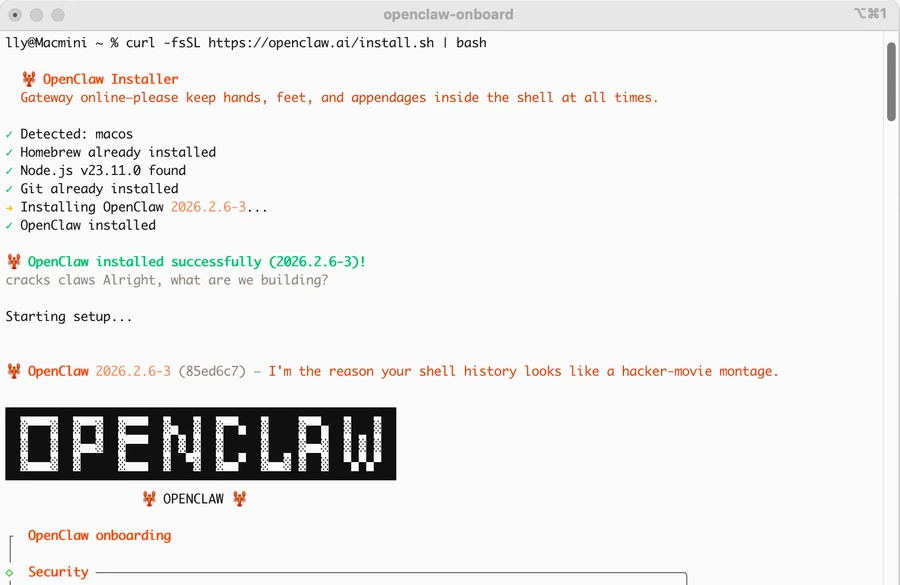
我只暂且试了下读取日历的功能,但就发现磕磕绊绊的,不是很顺利的样子。虽然最终是读取成功了。
点击查看全文 »
这次南美之行,去了半个月,发现AI圈又有了一些新的变化。有只龙虾,从ClawBot改名成了OpenClaw,似乎挺火的。。。
回来也有几天了,想跟上大家的步伐,于是也决定尝试一下。
安装的体验倒是非常好,按着官网来,给配上大模型的key(我用的是anthropic/claude-sonnet-4-5)、链接WhatsApp、开一些skills,就能用了。。
我只暂且试了下读取日历的功能,但就发现磕磕绊绊的,不是很顺利的样子。虽然最终是读取成功了。
点击查看全文 »
查尔滕(El Chaltén)位于阿根廷巴塔哥尼亚地区,被誉为徒步胜地。这是一个比卡拉法特还要小的小镇,没有机场,所有绝大部分到查尔滕的游客,都会经过卡拉法特到再转到这里。
从卡拉法特到查尔滕,大约2个多小时车程,一路的风景已经非常棒了,而且沿途有多个观景点,能看到雪山、阿根廷湖和另一个什么湖。但要看Patagonia标志性的菲茨罗伊峰(Fitz Roy),最好在这个 (-49.4197,-72.7139) 这个坐标停车,你就能拍到这样的景色:

我们是在卡拉法特吃过早午饭后,一路边拍照边看风景,慢悠悠开到查尔滕的,到的时候也就下午3点的样子。而当地的日落时间在晚上9点40左右(对,高纬度的夏天就是这样的),所以我们还有充足的时间去走一条小的徒步路线:Laguna Torre(托雷山路线)。
这条路线走完的话,往返也有18km,大概需要8个小时,终点据说是以托雷山的背景的一个冰川湖。我们刚到此地,加上第二天计划早起去看日出,所以就把这半天的徒步作为练手。因此并没有走完的计划,而是走到2小时的地方,就折返,为明天节省体力。
点击查看全文 »
继续接上篇,在圣保罗跑完半马后,我们回到酒店,洗个澡休整了一下,匆匆忙忙间就到了要退房的时间了。而我们到阿根廷的机票是在下午6点起飞,算上要去机场附近还车,其实还有点时间,但又不足以去其他的景点了。于是我施放了旅行期间的惯用技能:打开地图点一个看着是绿色的顺眼的区域,就开着车过去了!
没想到就这么一点,我们就到了 圣保罗·伊比拉布埃拉公园(Parque Ibirapuera),这是圣保罗最重要、也最有代表性的城市公园,其地位相当于纽约的Central Park。里面有大片的草地、树林,还有一个小湖。在此跑步、骑车、遛娃、野餐的人们三三两两地点缀其间,看着就让人心旷神怡!
草地上甚至还有两队人,拿着塑胶的刀枪棍棒,在玩模拟战争的游戏,虽然没看明白具体是什么规则,但看着大家都沉浸其中,想必是很好玩的。

好像有点偏题了,本篇要讲卡拉法特来着。
那就快进一下,18点从圣保罗出发,坐一程3个小时的飞机,就到了阿根廷的布宜诺斯艾利斯的AEP机场。
阿根廷对中国护照,是有条件免签,这个条件就是你有“有效的美签或者申根签”,因为我的美签其实不到半年有效期了(感叹一下,10年了)。虽然之前查过说问题不大,但真正入境前,多少还是有点担心的,因为秘鲁、智利都是类似政策,但都要求美签有效期大于半年。
没想到的是,我的入境非常丝滑。反而是刚刚办了美签的小L同学,因为新的美签从来没有使用过,而被卡住了一下。好在签证官搞了一通不知道什么操作以后,也算顺利入关了。
此时,已经接近23点了,而我们今晚是没有住宿的。。。因为我们要赶到布市的另外一个机场(EZE),然后坐早上6点起飞的航班,到卡拉法特。
点击查看全文 »
接着上篇,继续写一些我在巴西的见闻。
其实,这周主要是在圣保罗出差,所以可写的东西并不是很多。巴西当地的同事确实非常热情,带着我们在两个办公楼都转了转,并且安排了一堆的会议。大家都表示之前还是聊得太少了,我们做的很多功能,巴西这边都不知道;巴西同事的很多需求,我们也没有get到细节,有种相见恨晚的感觉。不过这其实情有可原,毕竟有11个小时到时差,沟通确实会受限。
这里不说太多工作的事情了(大家肯定也不是来看这个的),有个有意思的事情是:这边吃饭都流行AA,我们和巴西同事吃饭,也都是AA,唯一一顿被请客,还是因为巴西这边有个过来轮岗的中国人(她叫曼谷,在此特别感谢🙏)和我们一起吃了个饭。这都是文化如此,倒也无可厚非。
周六,终于空下来了,我们租了个车,去了趟桑托斯。
桑托斯,这边的葡语叫Santos,是圣保罗下面的一个港口城市,从圣保罗开车过来,要一个多小时。这座城市,以咖啡和贝利(球王)而闻名,因此,主要的景点就是:咖啡博物馆和贝利博物馆。
点击查看全文 »
书接上回,我们在里约短暂休整以后,就到本次行程的重点了,那就是:圣保罗出差!对,其实我们本次是商务出行,哈哈。
截止到写这文章的时候,已经在公司上了两天班了,加上时差还没倒利索,经常处在困困的状态。而且也还完全没有时间出去玩。因此,我想只写一写圣保罗的交通状况。
如果用一个字形容圣保罗的交通,那肯定就是“堵”了,以我的感觉来看,比国内的北京、杭州等著名堵城都还要更堵一些。翻了一下我的Uber行程,今天的两个单子,分别是 3.6km和7.7km,在上下班期间,分别用了 31分钟和43分钟,上班高峰期的时速不到7km/h,真的没有走路快!
我观察了一下,这么慢的原因,除了人多、车多以外,还有一个非常不利的因素:红绿灯多。
我目测有些路段大概两三百米就有一个红绿灯。
再究其根因,我觉得是这边没有类似国内的“小区”的感念,基本上一栋楼就是一个小区,然后一栋楼就不会特别大,所以基本上整个地块就分割成了非常小的正方形,这些正方形的边,自然就是大马路了;而那些顶点上,就都是红绿灯了。
虽然有不少新闻,说到圣保罗实施了类似国内“绿波带”的智能信号灯系统,但我感觉情况还是非常糟糕的。
另外,这边的车道设置也非常有意思,下图是从谷歌街景截的,从马路中间到最右边分别是:自行车道、绿化带、车道、摩托车道、车道、车道、车道、绿化带、人行道;看着虽然非常严谨,但也解决不了拥堵问题!

那么,有没有解决办法呢?或者说,富人有没有解决拥堵问题的招呢?答案当然是有的,只要使用钞能力!坐直升飞机上班就好了嘛!在圣保罗的CBD,写字楼集中区域,很多办公楼的楼顶都是停机坪,至少老板们是不用为堵车发愁的,哈哈!

里约热内卢,简称里约。但这并不是巴西的首都,同样的,圣保罗也不是巴西的首都。至于巴西的首都是哪?我并没有打算告诉你,你自己去查,嘿嘿!
我们的南美之旅,第一站就在这座城市了!
经过接近24小时的飞行,我们来到了这座一听就很热情、奔放的城市。你要问我第一印象是什么的话,我会说:热。35度左右的气温,如果有太阳的话,即使在新加坡待习惯了的我,也还是觉得有点热的。
我们是在Airbnb上定的房子,这个房子的风景非常赞👍,以至于我舍得放3张图,哈哈!

点击查看全文 »
从今天开始,未来的两周都将在南美洲度过。
我先会在巴西出差一周,再去阿根廷玩一周。此前我也从未涉足南美,也不知道接下来会遇到什么。
我将在这里不定期更新一下南美的见闻。但大概是以流水账为主,但贵在真实。
我是凌晨从新加坡出发的,机票是从迪拜中转的emirates航空的,发现樟宜机场的自助值机这次终于能正常使用了,试了下居然顺利取到了登机牌,而且选的还是比较好的twin seats(见后图)。
点击查看全文 »
如果你买过YouTube premium,或者加过其他人买的YouTube premium family套餐,后续又因为种种原因(比如Google 封禁了假的土耳其区等)退出了premium计划,那你再想加入另一个family的时候,大概率会看到这么一个提示:告诉你“您似乎与邀请您的人不在同一个国家/地区。”,从而“无法加入家人群组”。

然后,你可以会在Google账号的后台管理账号做各种尝试,包括用不同国家的VPN,拿到特定的IP地址、修改账号的住址信息、添加不同国家的信用卡作为付款方式等等,但我猜这大概率都解决不了你的问题!
我曾经也因此折腾了很久,知道最近,才明白怎么查看以及修改这个字段。先说好:方法仅供参考,也别拿大号玩得太花,不然被封就嘎了~
先得有办法确认当前的账号所属国家,才知道要不要去做修改。
这个方法很简单,登陆Google Play的web页面,登陆以后,确定右上角的头像是要查看的账号头像,然后把页面拉到最底部,右下角就会显示 国家(语言)。
这可能是唯一精确知道目前账号所属国的办法。
如果确定了你的国家不是你想要的,要怎么修改呢?
以下几乎也是唯一可行的办法:
点击查看全文 »
在读完《人类群星闪耀时》之后,我就开始读这本《静静的顿河》了,由于此书篇幅比较大,我不想整本读完再写读后感,所以,就在看完前两卷之后,就先来水这么一篇了。
要读懂《静静的顿河》首先得理解一个概念,因为会在书中反复出现,那就是“哥萨克”,这个概念基本是就是指 俄国南部边疆地区(顿河就在这个地区)的半军事化自由民群体。他们介于农奴和军人之间,闲时务农、战时为兵,或者一个家庭会出部分“壮丁”去当兵,以维持这个小团体的利益。
作者肖洛霍夫,自己就是出生于顿河地区的哥萨克家庭,所以,某种意义上来说,这本书并不是虚构的小说,而是纪实文学,或者干脆是回忆录。当然,在此书获得诺贝尔文学奖之后,很多人都对书中情节的真实性提出质疑,但无法质疑的是此书的文学地位。
这种文学性,也会体现在它描述的“画面感”上,书中描写的顿河地区的景色,在我脑海里是那种“冬天的江南平原”的景色,水草丰美的鱼米之乡,适合放牧耕种,但天气略微偏冷一些。人民的生活属于清贫但又充实的,除了偶尔会被召唤入伍以外,基本上也是挺幸福的。
也体现在细腻的人物刻画上,会通过大量的对白,以及心理活动的描写,把一个个人物刻画地栩栩如生。我觉得,如果要拍电影或者电视剧的话,基本上只需要小小的修改,就可以直接当作演出脚本使用了。
由于以上原因,加上中文译者(金人)的水平也很高,这本书读起来相对很舒服,就像是看一部情节缓缓推进的电影,经常会有停不下来的感觉。
当然,前两卷基本上还处于交代背景、铺垫人设的阶段(我感觉是这样),虽然已经出现了马克思,但只是刚刚提起一点点。大部分内容都是家长里短、儿女情长这类。我还挺期待这样一个葛利沙,在后续的战争、革命等社会巨变面前,会产生什么戏剧性的冲突,我会拭目以待!
点击查看全文 »
过度医疗似乎是发达国家的通病,之前有听说美国、欧洲都有这种情况,以诊疗费用为目的过度医疗,而且在这个领域,由于信息差巨大,病人几乎没有办法讨价还价。巨额诊疗费和保险一起,构成了一个很别扭的存在。
今天我也算是亲身体验了一把新加坡的过度医疗。
起因是我家娃左脚的大拇指长了嵌甲,一年多了,那指甲长出来的时候就会戳到边上的肉,有时候还会红肿化脓,自己也试过很多办法都没有根治,好一阵坏一阵的,感觉也不是个事,于是就带着去小诊所看了一下,医生表示这个搞不定,需要介绍到大医院去看下。
于是经过排队,上周看到了专家医生,说是要动个小手术,把部分组织切除。而且也不能当场手术,需要再预约时间。
我们觉得也算合理,就约到了今天10点去做手术。至此都挺正常的。
今天一早,我们就去医院了,想着应该可以赶回来吃午饭吧。10点准时到了以后,接待的人已经提前把上下文了解了,这点体验非常好,开了手术的单子,并且把术后的消炎、镇痛的药都给我们以后,说手术的地点是另一个分院,已经帮我们预约了11点的时间,还得让我们赶过去一趟,因为那边的费用会便宜一些。
那好吧,我们就赶到新的地方,再经过登记、缴费等流程,就由护士引导到病房里,说要换衣服。自此,画风就有点不对劲了。
点击查看全文 »