分类: '精华' 的归档
《SED单行脚本快速参考》的 awk 实现
sed和awk都是linux下常用的流编辑器,他们各有各的特色,本文并不是要做什么对比,而是权当好玩,把《SED单行脚本快速参考》这文章,用awk做了一遍~
至于孰好孰坏,那真是很难评论了。一般来说,sed的命令会更短小一些,同时也更难读懂;而awk稍微长点,但是if、while这样的,逻辑性比较强,更加像“程序”。到底喜欢用哪个,就让各位看官自己决定吧!
PS: 貌似这个配色,单行的代码多了以后,拖动的时候会有点眼花的感觉,将就下吧,呵呵。
文本间隔:
——–
# 在每一行后面增加一空行
|
1 |
sed G |
|
1 |
awk '{printf("%s\n\n",$0)}' |
# 将原来的所有空行删除并在每一行后面增加一空行。
# 这样在输出的文本中每一行后面将有且只有一空行。
|
1 |
sed '/^$/d;G' |
|
1 |
awk '!/^$/{printf("%s\n\n",$0)}' |
# 在每一行后面增加两行空行
|
1 |
sed 'G;G' |
|
1 |
awk '{printf("%s\n\n\n",$0)}' |
# 将第一个脚本所产生的所有空行删除(即删除所有偶数行)
|
1 |
sed 'n;d' |
|
1 |
awk '{f=!f;if(f)print $0}' |
# 在匹配式样“regex”的行之前插入一空行
|
1 |
sed '/regex/{x;p;x;}' |
|
1 |
awk '{if(/regex/)printf("\n%s\n",$0);else print $0}' |
# 在匹配式样“regex”的行之后插入一空行
|
1 |
sed '/regex/G' |
|
1 |
awk '{if(/regex/)printf("%s\n\n",$0);else print $0}' |
# 在匹配式样“regex”的行之前和之后各插入一空行
|
1 |
sed '/regex/{x;p;x;G;}' |
|
1 |
awk '{if(/regex/)printf("\n%s\n\n",$0);else print $0}' |
编号:
——–
# 为文件中的每一行进行编号(简单的左对齐方式)。这里使用了“制表符”
# (tab,见本文末尾关于’\t’的用法的描述)而不是空格来对齐边缘。
|
1 |
sed = filename | sed 'N;s/\n/\t/' |
|
1 |
awk '{i++;printf("%d\t%s\n",i,$0)}' |
# 对文件中的所有行编号(行号在左,文字右端对齐)。
|
1 |
sed = filename | sed 'N; s/^/ /; s/ *\(.\{6,\}\)\n/\1 /' |
|
1 |
awk '{i++;printf("%6d %s\n",i,$0)}' |
# 对文件中的所有行编号,但只显示非空白行的行号。
|
1 |
sed '/./=' filename | sed '/./N; s/\n/ /' |
|
1 |
awk '{i++;if(!/^$/)printf("%d %s\n",i,$0);else print}' |
# 计算行数 (模拟 “wc -l”)
|
1 |
sed -n '$=' |
|
1 |
awk '{i++}END{print i}' |
文本转换和替代:
——–
# Unix环境:转换DOS的新行符(CR/LF)为Unix格式。
|
1 2 3 |
sed 's/.$//' # 假设所有行以CR/LF结束 sed 's/^M$//' # 在bash/tcsh中,将按Ctrl-M改为按Ctrl-V sed 's/\x0D$//' # ssed、gsed 3.02.80,及更高版本 |
|
1 |
awk '{sub(/\x0D$/,"");print $0}' |
# Unix环境:转换Unix的新行符(LF)为DOS格式。
|
1 2 3 4 |
sed "s/$/`echo -e \\\r`/" # 在ksh下所使用的命令 sed 's/$'"/`echo \\\r`/" # 在bash下所使用的命令 sed "s/$/`echo \\\r`/" # 在zsh下所使用的命令 sed 's/$/\r/' # gsed 3.02.80 及更高版本 |
|
1 |
awk '{printf("%s\r\n",$0)}' |
# DOS环境:转换Unix新行符(LF)为DOS格式。
|
1 2 |
sed "s/$//" # 方法 1 sed -n p # 方法 2 |
|
1 |
DOS环境的略过 |
# DOS环境:转换DOS新行符(CR/LF)为Unix格式。
# 下面的脚本只对UnxUtils sed 4.0.7 及更高版本有效。要识别UnxUtils版本的
# sed可以通过其特有的“–text”选项。你可以使用帮助选项(“–help”)看
# 其中有无一个“–text”项以此来判断所使用的是否是UnxUtils版本。其它DOS
# 版本的的sed则无法进行这一转换。但可以用“tr”来实现这一转换。
|
1 2 |
sed "s/\r//" infile >outfile # UnxUtils sed v4.0.7 或更高版本 tr -d \r <infile >outfile # GNU tr 1.22 或更高版本 |
|
1 |
DOS环境的略过 |
# 将每一行前导的“空白字符”(空格,制表符)删除
# 使之左对齐
|
1 |
sed 's/^[ \t]*//' # 见本文末尾关于'\t'用法的描述 |
|
1 |
awk '{sub(/^[ \t]+/,"");print $0}' |
# 将每一行拖尾的“空白字符”(空格,制表符)删除
|
1 |
sed 's/[ \t]*$//' # 见本文末尾关于'\t'用法的描述 |
|
1 |
awk '{sub(/[ \t]+$/,"");print $0}' |
# 将每一行中的前导和拖尾的空白字符删除
|
1 |
sed 's/^[ \t]*//;s/[ \t]*$//' |
|
1 |
awk '{sub(/^[ \t]+/,"");sub(/[ \t]+$/,"");print $0}' |
# 在每一行开头处插入5个空格(使全文向右移动5个字符的位置)
|
1 |
sed 's/^/ /' |
|
1 |
awk '{printf(" %s\n",$0)}' |
# 以79个字符为宽度,将所有文本右对齐
# 78个字符外加最后的一个空格
|
1 |
sed -e :a -e 's/^.\{1,78\}$/ &/;ta' |
|
1 |
awk '{printf("%79s\n",$0)}' |
# 以79个字符为宽度,使所有文本居中。在方法1中,为了让文本居中每一行的前
# 头和后头都填充了空格。 在方法2中,在居中文本的过程中只在文本的前面填充
# 空格,并且最终这些空格将有一半会被删除。此外每一行的后头并未填充空格。
|
1 2 |
sed -e :a -e 's/^.\{1,77\}$/ & /;ta' # 方法1 sed -e :a -e 's/^.\{1,77\}$/ &/;ta' -e 's/\( *\)\1/\1/' # 方法2 |
|
1 |
awk '{for(i=0;i<39-length($0)/2;i++)printf(" ");printf("%s\n",$0)}' #相当于上面的方法二 |
# 在每一行中查找字串“foo”,并将找到的“foo”替换为“bar”
|
1 2 3 4 5 |
sed 's/foo/bar/' # 只替换每一行中的第一个“foo”字串 sed 's/foo/bar/4' # 只替换每一行中的第四个“foo”字串 sed 's/foo/bar/g' # 将每一行中的所有“foo”都换成“bar” sed 's/\(.*\)foo\(.*foo\)/\1bar\2/' # 替换倒数第二个“foo” sed 's/\(.*\)foo/\1bar/' # 替换最后一个“foo” |
|
1 |
awk '{gsub(/foo/,"bar");print $0}' # 将每一行中的所有“foo”都换成“bar” |
# 只在行中出现字串“baz”的情况下将“foo”替换成“bar”
|
1 |
sed '/baz/s/foo/bar/g' |
|
1 |
awk '{if(/baz/)gsub(/foo/,"bar");print $0}' |
# 将“foo”替换成“bar”,并且只在行中未出现字串“baz”的情况下替换
|
1 |
sed '/baz/!s/foo/bar/g' |
|
1 |
awk '{if(/baz$/)gsub(/foo/,"bar");print $0}' |
# 不管是“scarlet”“ruby”还是“puce”,一律换成“red”
|
1 2 |
sed 's/scarlet/red/g;s/ruby/red/g;s/puce/red/g' #对多数的sed都有效 gsed 's/scarlet\|ruby\|puce/red/g' # 只对GNU sed有效 |
|
1 |
awk '{gsub(/scarlet|ruby|puce/,"red");print $0}' |
# 倒置所有行,第一行成为最后一行,依次类推(模拟“tac”)。
# 由于某些原因,使用下面命令时HHsed v1.5会将文件中的空行删除
|
1 2 |
sed '1!G;h;$!d' # 方法1 sed -n '1!G;h;$p' # 方法2 |
|
1 |
awk '{A[i++]=$0}END{for(j=i-1;j>=0;j--)print A[j]}' |
# 将行中的字符逆序排列,第一个字成为最后一字,……(模拟“rev”)
|
1 |
sed '/\n/!G;s/\(.\)\(.*\n\)/&\2\1/;//D;s/.//' |
|
1 |
awk '{for(i=length($0);i>0;i--)printf("%s",substr($0,i,1));printf("\n")}' |
# 将每两行连接成一行(类似“paste”)
|
1 |
sed '$!N;s/\n/ /' |
|
1 |
awk '{f=!f;if(f)printf("%s",$0);else printf(" %s\n",$0)}' |
# 如果当前行以反斜杠“\”结束,则将下一行并到当前行末尾
# 并去掉原来行尾的反斜杠
|
1 |
sed -e :a -e '/\\$/N; s/\\\n//; ta' |
|
1 |
awk '{if(/\\$/)printf("%s",substr($0,0,length($0)-1));else printf("%s\n",$0)}' |
# 如果当前行以等号开头,将当前行并到上一行末尾
# 并以单个空格代替原来行头的“=”
|
1 |
sed -e :a -e '$!N;s/\n=/ /;ta' -e 'P;D' |
|
1 |
awk '{if(/^=/)printf(" %s",substr($0,2));else printf("%s%s",a,$0);a="\n"}END{printf("\n")}' |
# 为数字字串增加逗号分隔符号,将“1234567”改为“1,234,567”
|
1 2 |
gsed ':a;s/\B[0-9]\{3\}\>/,&/;ta' # GNU sed sed -e :a -e 's/\(.*[0-9]\)\([0-9]\{3\}\)/\1,\2/;ta' # 其他sed |
|
1 2 |
#awk的正则没有后向匹配和引用,搞的比较狼狈,呵呵。 awk '{while(match($0,/[0-9][0-9][0-9][0-9]+/)){$0=sprintf("%s,%s",substr($0,0,RSTART+RLENGTH-4),substr($0,RSTART+RLENGTH-3))}print $0}' |
# 为带有小数点和负号的数值增加逗号分隔符(GNU sed)
|
1 |
gsed -r ':a;s/(^|[^0-9.])([0-9]+)([0-9]{3})/\1\2,\3/g;ta' |
|
1 2 |
#和上例差不多 awk '{while(match($0,/[^\.0-9][0-9][0-9][0-9][0-9]+/)){$0=sprintf("%s,%s",substr($0,0,RSTART+RLENGTH-4),substr($0,RSTART+RLENGTH-3))}print $0}' |
# 在每5行后增加一空白行 (在第5,10,15,20,等行后增加一空白行)
|
1 2 |
gsed '0~5G' # 只对GNU sed有效 sed 'n;n;n;n;G;' # 其他sed |
|
1 |
awk '{print $0;i++;if(i==5){printf("\n");i=0}}' |
选择性地显示特定行:
——–
# 显示文件中的前10行 (模拟“head”的行为)
|
1 |
sed 10q |
|
1 |
awk '{print;if(NR==10)exit}' |
# 显示文件中的第一行 (模拟“head -1”命令)
|
1 |
sed q |
|
1 |
awk '{print;exit}' |
# 显示文件中的最后10行 (模拟“tail”)
|
1 |
sed -e :a -e '$q;N;11,$D;ba' |
|
1 2 |
#用awk干这个有点亏,得全文缓存,对于大文件肯定很慢 awk '{A[NR]=$0}END{for(i=NR-9;i<=NR;i++)print A[i]}' |
# 显示文件中的最后2行(模拟“tail -2”命令)
|
1 |
sed '$!N;$!D' |
|
1 |
awk '{A[NR]=$0}END{for(i=NR-1;i<=NR;i++)print A[i]}' |
# 显示文件中的最后一行(模拟“tail -1”)
|
1 2 |
sed '$!d' # 方法1 sed -n '$p' # 方法2 |
|
1 2 |
#这个比较好办,只存最后一行了。 awk '{A=$0}END{print A}' |
# 显示文件中的倒数第二行
|
1 2 3 |
sed -e '$!{h;d;}' -e x # 当文件中只有一行时,输出空行 sed -e '1{$q;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,显示该行 sed -e '1{$d;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,不输出 |
|
1 2 |
#存两行呗(当文件中只有一行时,输出空行) awk '{B=A;A=$0}END{print B}' |
# 只显示匹配正则表达式的行(模拟“grep”)
|
1 2 |
sed -n '/regexp/p' # 方法1 sed '/regexp/!d' # 方法2 |
|
1 |
awk '/regexp/{print}' |
# 只显示“不”匹配正则表达式的行(模拟“grep -v”)
|
1 2 |
sed -n '/regexp/!p' # 方法1,与前面的命令相对应 sed '/regexp/d' # 方法2,类似的语法 |
|
1 |
awk '!/regexp/{print}' |
# 查找“regexp”并将匹配行的上一行显示出来,但并不显示匹配行
|
1 |
sed -n '/regexp/{g;1!p;};h' |
|
1 |
awk '/regexp/{print A}{A=$0}' |
# 查找“regexp”并将匹配行的下一行显示出来,但并不显示匹配行
|
1 |
sed -n '/regexp/{n;p;}' |
|
1 |
awk '{if(A)print;A=0}/regexp/{A=1}' |
# 显示包含“regexp”的行及其前后行,并在第一行之前加上“regexp”所在行的行号 (类似“grep -A1 -B1”)
|
1 |
sed -n -e '/regexp/{=;x;1!p;g;$!N;p;D;}' -e h |
|
1 |
awk '{if(F)print;F=0}/regexp/{print NR;print b;print;F=1}{b=$0}' |
# 显示包含“AAA”、“BBB”和“CCC”的行(任意次序)
|
1 |
sed '/AAA/!d; /BBB/!d; /CCC/!d' # 字串的次序不影响结果 |
|
1 |
awk '{if(match($0,/AAA/) && match($0,/BBB/) && match($0,/CCC/))print}' |
# 显示包含“AAA”、“BBB”和“CCC”的行(固定次序)
|
1 |
sed '/AAA.*BBB.*CCC/!d' |
|
1 |
awk '{if(match($0,/AAA.*BBB.*CCC/))print}' |
# 显示包含“AAA”“BBB”或“CCC”的行 (模拟“egrep”)
|
1 2 |
sed -e '/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d # 多数sed gsed '/AAA\|BBB\|CCC/!d' # 对GNU sed有效 |
|
1 2 |
awk '/AAA/{print;next}/BBB/{print;next}/CCC/{print}' awk '/AAA|BBB|CCC/{print}' |
# 显示包含“AAA”的段落 (段落间以空行分隔)
# HHsed v1.5 必须在“x;”后加入“G;”,接下来的3个脚本都是这样
|
1 |
sed -e '/./{H;$!d;}' -e 'x;/AAA/!d;' |
|
1 2 |
awk 'BEGIN{RS=""}/AAA/{print}' awk -vRS= '/AAA/{print}' |
# 显示包含“AAA”“BBB”和“CCC”三个字串的段落 (任意次序)
|
1 |
sed -e '/./{H;$!d;}' -e 'x;/AAA/!d;/BBB/!d;/CCC/!d' |
|
1 |
awk -vRS= '{if(match($0,/AAA/) && match($0,/BBB/) && match($0,/CCC/))print}' |
# 显示包含“AAA”、“BBB”、“CCC”三者中任一字串的段落 (任意次序)
|
1 2 |
sed -e '/./{H;$!d;}' -e 'x;/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d gsed '/./{H;$!d;};x;/AAA\|BBB\|CCC/b;d' # 只对GNU sed有效 |
|
1 |
awk -vRS= '/AAA|BBB|CCC/{print "";print}' |
# 显示包含65个或以上字符的行
|
1 |
sed -n '/^.\{65\}/p' |
|
1 |
cat ll.txt | awk '{if(length($0)>=65)print}' |
# 显示包含65个以下字符的行
|
1 2 |
sed -n '/^.\{65\}/!p' # 方法1,与上面的脚本相对应 sed '/^.\{65\}/d' # 方法2,更简便一点的方法 |
|
1 |
awk '{if(length($0)<=65)print}' |
# 显示部分文本——从包含正则表达式的行开始到最后一行结束
|
1 |
sed -n '/regexp/,$p' |
|
1 |
awk '/regexp/{F=1}{if(F)print}' |
# 显示部分文本——指定行号范围(从第8至第12行,含8和12行)
|
1 2 |
sed -n '8,12p' # 方法1 sed '8,12!d' # 方法2 |
|
1 |
awk '{if(NR>=8 && NR<12)print}' |
# 显示第52行
|
1 2 3 |
sed -n '52p' # 方法1 sed '52!d' # 方法2 sed '52q;d' # 方法3, 处理大文件时更有效率 |
|
1 |
awk '{if(NR==52){print;exit}}' |
# 从第3行开始,每7行显示一次
|
1 2 |
gsed -n '3~7p' # 只对GNU sed有效 sed -n '3,${p;n;n;n;n;n;n;}' # 其他sed |
|
1 |
awk '{if(NR==3)F=1}{if(F){i++;if(i%7==1)print}}' |
# 显示两个正则表达式之间的文本(包含)
|
1 |
sed -n '/Iowa/,/Montana/p' # 区分大小写方式 |
|
1 |
awk '/Iowa/{F=1}{if(F)print}/Montana/{F=0}' |
选择性地删除特定行:
——–
# 显示通篇文档,除了两个正则表达式之间的内容
|
1 |
sed '/Iowa/,/Montana/d' |
|
1 |
awk '/Iowa/{F=1}{if(!F)print}/Montana/{F=0}' |
# 删除文件中相邻的重复行(模拟“uniq”)
# 只保留重复行中的第一行,其他行删除
|
1 |
sed '$!N; /^\(.*\)\n\1$/!P; D' |
|
1 |
awk '{if($0!=B)print;B=$0}' |
# 删除文件中的重复行,不管有无相邻。注意hold space所能支持的缓存大小,或者使用GNU sed。
|
1 |
sed -n 'G; s/\n/&&/; /^\([ -~]*\n\).*\n\1/d; s/\n//; h; P' #bones7456注:我这里此命令并不能正常工作 |
|
1 |
awk '{if(!($0 in B))print;B[$0]=1}' |
# 删除除重复行外的所有行(模拟“uniq -d”)
|
1 |
sed '$!N; s/^\(.*\)\n\1$/\1/; t; D' |
|
1 |
awk '{if($0==B && $0!=l){print;l=$0}B=$0}' |
# 删除文件中开头的10行
|
1 |
sed '1,10d' |
|
1 |
awk '{if(NR>10)print}' |
# 删除文件中的最后一行
|
1 |
sed '$d' |
|
1 2 |
#awk在过程中并不知道文件一共有几行,所以只能通篇缓存,大文件可能不适合,下面两个也一样 awk '{B[NR]=$0}END{for(i=0;i<=NR-1;i++)print B[i]}' |
# 删除文件中的最后两行
|
1 |
sed 'N;$!P;$!D;$d' |
|
1 |
awk '{B[NR]=$0}END{for(i=0;i<=NR-2;i++)print B[i]}' |
# 删除文件中的最后10行
|
1 2 |
sed -e :a -e '$d;N;2,10ba' -e 'P;D' # 方法1 sed -n -e :a -e '1,10!{P;N;D;};N;ba' # 方法2 |
|
1 |
awk '{B[NR]=$0}END{for(i=0;i<=NR-10;i++)print B[i]}' |
# 删除8的倍数行
|
1 2 |
gsed '0~8d' # 只对GNU sed有效 sed 'n;n;n;n;n;n;n;d;' # 其他sed |
|
1 |
awk '{if(NR%8!=0)print}' |head |
# 删除匹配式样的行
|
1 |
sed '/pattern/d' # 删除含pattern的行。当然pattern可以换成任何有效的正则表达式 |
|
1 |
awk '{if(!match($0,/pattern/))print}' |
# 删除文件中的所有空行(与“grep ‘.’ ”效果相同)
|
1 2 |
sed '/^$/d' # 方法1 sed '/./!d' # 方法2 |
|
1 |
awk '{if(!match($0,/^$/))print}' |
# 只保留多个相邻空行的第一行。并且删除文件顶部和尾部的空行。
# (模拟“cat -s”)
|
1 2 |
sed '/./,/^$/!d' #方法1,删除文件顶部的空行,允许尾部保留一空行 sed '/^$/N;/\n$/D' #方法2,允许顶部保留一空行,尾部不留空行 |
|
1 |
awk '{if(!match($0,/^$/)){print;F=1}else{if(F)print;F=0}}' #同上面的方法2 |
# 只保留多个相邻空行的前两行。
|
1 |
sed '/^$/N;/\n$/N;//D' |
|
1 |
awk '{if(!match($0,/^$/)){print;F=0}else{if(F<2)print;F++}}' |
# 删除文件顶部的所有空行
|
1 |
sed '/./,$!d' |
|
1 |
awk '{if(F || !match($0,/^$/)){print;F=1}}' |
# 删除文件尾部的所有空行
|
1 2 |
sed -e :a -e '/^\n*$/{$d;N;ba' -e '}' # 对所有sed有效 sed -e :a -e '/^\n*$/N;/\n$/ba' # 同上,但只对 gsed 3.02.*有效 |
|
1 |
awk '/^.+$/{for(i=l;i<NR-1;i++)print "";print;l=NR}' |
# 删除每个段落的最后一行
|
1 |
sed -n '/^$/{p;h;};/./{x;/./p;}' |
|
1 2 |
#很长,很ugly,应该有更好的办法 awk -vRS= '{B=$0;l=0;f=1;while(match(B,/\n/)>0){print substr(B,l,RSTART-l-f);l=RSTART;sub(/\n/,"",B);f=0};print ""}' |
特殊应用:
——–
# 移除手册页(man page)中的nroff标记。在Unix System V或bash shell下使
# 用’echo’命令时可能需要加上 -e 选项。
|
1 2 3 |
sed "s/.`echo \\\b`//g" # 外层的双括号是必须的(Unix环境) sed 's/.^H//g' # 在bash或tcsh中, 按 Ctrl-V 再按 Ctrl-H sed 's/.\x08//g' # sed 1.5,GNU sed,ssed所使用的十六进制的表示方法 |
|
1 |
awk '{gsub(/.\x08/,"",$0);print}' |
# 提取新闻组或 e-mail 的邮件头
|
1 |
sed '/^$/q' # 删除第一行空行后的所有内容 |
|
1 |
awk '{print}/^$/{exit}' |
# 提取新闻组或 e-mail 的正文部分
|
1 |
sed '1,/^$/d' # 删除第一行空行之前的所有内容 |
|
1 |
awk '{if(F)print}/^$/{F=1}' |
# 从邮件头提取“Subject”(标题栏字段),并移除开头的“Subject:”字样
|
1 |
sed '/^Subject: */!d; s///;q' |
|
1 |
awk '/^Subject:.*/{print substr($0,10)}/^$/{exit}' |
# 从邮件头获得回复地址
|
1 |
sed '/^Reply-To:/q; /^From:/h; /./d;g;q' |
|
1 2 |
#好像是输出第一个Reply-To:开头的行?From是干啥用的?不清楚规则。。 awk '/^Reply-To:.*/{print;exit}/^$/{exit}' |
# 获取邮件地址。在上一个脚本所产生的那一行邮件头的基础上进一步的将非电邮地址的部分剃除。(见上一脚本)
|
1 |
sed 's/ *(.*)//; s/>.*//; s/.*[:<] *//' |
|
1 2 |
#取尖括号里的东西吧? awk -F'[<>]+' '{print $2}' |
# 在每一行开头加上一个尖括号和空格(引用信息)
|
1 |
sed 's/^/> /' |
|
1 |
awk '{print "> " $0}' |
# 将每一行开头处的尖括号和空格删除(解除引用)
|
1 |
sed 's/^> //' |
|
1 |
awk '/^> /{print substr($0,3)}' |
# 移除大部分的HTML标签(包括跨行标签)
|
1 |
sed -e :a -e 's/<[^>]*>//g;/</N;//ba' |
|
1 |
awk '{gsub(/<[^>]*>/,"",$0);print}' |
# 将分成多卷的uuencode文件解码。移除文件头信息,只保留uuencode编码部分。
# 文件必须以特定顺序传给sed。下面第一种版本的脚本可以直接在命令行下输入;
# 第二种版本则可以放入一个带执行权限的shell脚本中。(由Rahul Dhesi的一
# 个脚本修改而来。)
|
1 2 |
sed '/^end/,/^begin/d' file1 file2 ... fileX | uudecode # vers. 1 sed '/^end/,/^begin/d' "$@" | uudecode # vers. 2 |
|
1 2 |
#我不想装个uudecode验证,大致写个吧 awk '/^end/{F=0}{if(F)print}/^begin/{F=1}' file1 file2 ... fileX |
# 将文件中的段落以字母顺序排序。段落间以(一行或多行)空行分隔。GNU sed使用
# 字元“\v”来表示垂直制表符,这里用它来作为换行符的占位符——当然你也可以
# 用其他未在文件中使用的字符来代替它。
|
1 2 |
sed '/./{H;d;};x;s/\n/={NL}=/g' file | sort | sed '1s/={NL}=//;s/={NL}=/\n/g' gsed '/./{H;d};x;y/\n/\v/' file | sort | sed '1s/\v//;y/\v/\n/' |
|
1 |
awk -vRS= '{gsub(/\n/,"\v",$0);print}' ll.txt | sort | awk '{gsub(/\v/,"\n",$0);print;print ""}' |
# 分别压缩每个.TXT文件,压缩后删除原来的文件并将压缩后的.ZIP文件
# 命名为与原来相同的名字(只是扩展名不同)。(DOS环境:“dir /b”
# 显示不带路径的文件名)。
|
1 2 |
echo @echo off >zipup.bat dir /b *.txt | sed "s/^\(.*\)\.TXT/pkzip -mo \1 \1.TXT/" >>zipup.bat |
|
1 |
DOS环境再次略过,而且我觉得这里用bash的参数 ${i%.TXT}.zip 替换更帅。 |
下面的一些SED说明略过,需要的朋友自行查看原文。
python 内建函数
说明:本文内容全部出自python官方文档,但是会有自己的理解,并非单纯的翻译。文章较长,如有错误之处,还请大家指正。
abs(x)
返回x的绝对值;当x是复数时,返回x的模。没错,python内建支持复数,见下面的complex()函数。
all(iterable)
当iterable里的每项都为真时,才返回真,等效于:
|
1 2 3 4 5 |
def all(iterable): for element in iterable: if not element: return False return True |
any(iterable)
只要iterable里有一项为真,就返回真,等效于:
|
1 2 3 4 5 |
def any(iterable): for element in iterable: if element: return True return False |
basestring()
这是 str 和 unicode 的抽象类,它不能被调用也不能被实例化,但是可以用在 isinstance 函数里进行判断,isinstance(obj, basestring) 等效于 isinstance(obj, (str, unicode)).
|
1 2 3 4 5 6 |
>>> isinstance(123, basestring) False >>> isinstance("123", basestring) True >>> isinstance(u"一二三", basestring) True |
bin(x)
如果x是一个整数,则返回一个与x等值的二进制python表达式;如果x不是一个整数类型,则x的类需要有一个可以返回一个整数的__index__()函数。
bool([x])
返回一个布尔型的值,如果x为False或者没传x参数的时候返回False,否则返回True。
callable(object)
判断object是否可调用,如果object是 函数、类、或者含有__call__()的类对象的话,将返回True。
chr(i)
返回一个单个字符的字符串,此字符的ascii码值为i(0<=i<=255),此函数是ord函数的反函数。如果参数大于255而想得到一个unicode字符的话,需要使用unichr()
classmethod(function)
返回一个类的方法(类的方法有别于实例的方法,是不需要实例化也可以通过类名访问的方法),定义一个类的方法需要用这样的形式:
|
1 2 3 |
class C: @classmethod def f(cls, arg1, arg2, ...): ... |
cmp(x, y)
比较两个对象x和y。如果x小于y,返回负数;大于返回正数;等于返回0。
compile(source, filename, mode[, flags[, dont_inherit]])
把source字符串编译成一个AST对象,暂时用不到,先略过。
complex([real[, imag]])
用传入的实部和虚部创建一个复数对象。
delattr(object, name)
删除对象的属性,相当于 del object.name ,可以和setattr配合使用。
dict([arg])
建立一个新的字典型数据,可以从参数里获取数据。
|
1 2 |
>>> dict({"a":"b","c":"d"}) {'a': 'b', 'c': 'd'} |
dir([object])
如果不加参数,返回当前执行环境下的变量名的列表。
如果加了object参数,则会根据复杂的规则得到object的属性名列表,需要注意的是,当object定义了__dir__()或者 __getattr__()方法时,返回的结果并不一定正确。
示例:
|
1 2 3 4 5 6 7 |
>>> dir() ['__builtins__', '__doc__', '__name__', '__package__'] >>> t=[1,2] >>> dir() ['__builtins__', '__doc__', '__name__', '__package__', 't'] >>> dir(t) ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__delslice__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getslice__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__setslice__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] |
divmod(a, b)
通常返回a和b的商和余数组成的元组: (a // b, a % b)。参数不能是复数。
enumerate(sequence[, start=0])
返回一个列举后的对象,sequence要支持迭代。返回的对象支持next()方法,此方法依次返回一个从start开始增长的序数和sequence里的元素组成的元组。看以下的例子:
|
1 2 3 4 5 6 7 8 9 10 |
>>> enu=enumerate(['Spring', 'Summer', 'Fall', 'Winter']) >>> enu.next() (0, 'Spring') >>> enu.next() (1, 'Summer') >>> for i, season in enu: ... print i, season ... 2 Fall 3 Winter |
eval(expression[, globals[, locals]])
执行expression表达式,可以用globals和locals来限制expression能访问的变量。
值得注意的是,expression不仅可以是明文的字符串,还可以是compile()函数返回的代码对象。
execfile(filename[, globals[, locals]])
此函数类似exec表达式。只是从文件里读取表达式。它和import的区别在于,execfile会无条件地读取文件,而且不会生成新的模块。
globals和locals的用法和上面的eval同理。
file(filename[, mode[, bufsize]])
File类型的构造函数,参数的作用和下面提到的open()函数是一样的。
值得注意的是,open()函数更适合于打开一个文件,而file函数更适用于类型测试,例如: isinstance(f, file)
filter(function, iterable)
构造一个function(iterable)为true的list。当然iterable为字符串或者tuple的时候,返回的类型也是字符串或者tuple,否则返回list。
|
1 2 3 4 5 6 |
>>> filter(lambda c: c in 'abc', 'abcdcba') 'abccba' >>> filter(lambda i: i < 3, (1, 2, 3, 2, 1)) (1, 2, 2, 1) >>> filter(lambda i: i < 3, [1, 2, 4, 2, 1]) [1, 2, 2, 1] |
如果function为None,则iterable为false的元素将被剔除。也就是说,function不为None的时候,filter(function, iterable)等效于[item for item in iterable if function(item)],否则等效于[item for item in iterable if item]
float([x])
传入一个字符串或者整数或者float,返回一个float数据。
format(value[, format_spec])
根据format_spec格式化输出value的值,实际上只是调用了value.__format__(format_spec),很多内建类型都有标准的输出函数。
frozenset([iterable])
由iterable创建一个frozenset对象,frozenset是set的一个子类,它和set的区别在于它不支持某些可以修改set的操作,例如:add、remove、pop、clear等。可以理解为一个set的常量。
getattr(object, name[, default])
获得对象的属性值,name必须是字符串,如果name是object的属性,则getattr(x, 'foobar')相当于x.foobar,如果name不是object的属性,则返回default,如果没有default就会抛出AttributeError意外。
globals()
返回一个包含当前“全局符号表”的dict。
hasattr(object, name)
参数是一个对象和一个字符串,如果object对象有名为name的属性,则返回True,否则返回False。在执行getattr(object, name)之前,可以以此来检测属性的存在性。
hash(object)
如果可能的话,返回object的hash值,hash值是一个整型的数字,用于快速比较两个对象。两个相等的数字型对象将有相同的hash值,比如:
|
1 2 |
>>> hash(1) == hash(1.0) True |
help([object])
调用内建的帮助系统(交互式)。
如果省略参数,则会进入帮助控制台,出现help>的提示符,输入相应内容就可以查看相应的帮助。
如果参数是字符串,则在模块名、函数名、类名、方法名、关键字及文档和帮助主题里搜索此字符串,并显示。
如果参数是其他类型的对象,则显示此对象的帮助信息。
hex(x)
将任何长度的整型数字转化为16进制的字符串。
如果转换浮点数为16进制,则须使用float.hex()方法。
id(object)
返回一个整型(或者长整型)的object的唯一标识符。注意:两个生命周期没有交叉的对象,也许会返回同一个标识符。(在CPython里,其实就是返回object的地址)
input([prompt])
等效于 eval(raw_input(prompt))
返回用户输入的python表达式的值,一句话:注意安全。
int([x[, base]])
根据x的值返回一个整数,x可以是一个含有数字信息的字符串或者数字类型(整型/浮点型/长整型/复数)。可选的base参数,代表进制,可以是2~36之间的数字或者0。如果base的值为0,将会根据x的值选取适当的基数。如果不提供任何参数,将返回0。
isinstance(object, classinfo)
如果object是classinfo或者classinfo的子类的实例,或者是和classinfo同类的对象,则返回True。classinfo也可以是类或者对象组成的tuple,这时候,object只要是classinfo里的一者就返回True:
|
1 2 3 4 5 6 |
>>> isinstance(1, (int,float) ) True >>> isinstance(1.0, (int,float) ) True >>> isinstance("1.0", (int,float) ) False |
issubclass(class, classinfo)
如果class是classinfo的直接或者间接之类的话,就返回True。一个类也被视为自己的之类。同上例,classinfo也可以是tuple。
iter(o[, sentinel])
返回一个“迭代器”对象,根据sentinel的设置不停地对第一个参数进线取值。当忽略第二个参数时,o必须是一个支持__iter__()或者__getitem__()方法的对象,否则将会抛出TypeError例外。如果提供了sentinel参数,o必须是一个可调用的对象,这时将不停地调用此方法,并返回迭代器的项,知道返回的值等于sentinel为止,这时将抛出StopIteration。
第二种形式特别适用于打开一个文件,一行行处理文本,知道遇到特定的行:
|
1 2 3 |
with open("mydata.txt") as fp: for line in iter(fp.readline, "STOP"): process_line(line) |
len(s)
返回s的长度,也就是项数。自建会调用__len__函数取值。
list([iterable])
返回一个含有所有iterable中的元素的list对象。如果参数为空,则返回空的list。
locals()
和上面的globals()对应,返回一个包含当前“局部符号表”的dict。在函数里调用的时候,将排除在类中声明的变量。
long([x[, base]])
根据字符串或者数字类型的参数,返回一个长整型的数字。参数的含义和上面的int类似。
map(function, iterable, …)
对iterable里的每项执行function函数,并把结果以一个list的形式返回。如果有3个以上的参数,则后面的参数也需要是可迭代的,map会把额外的参数传给function,例如,这样可以把两个tuple一一相加得到一个list:
|
1 2 |
>>> map(lambda x, add: x + add, (2, 4, 5), (1, 3, 6) ) [3, 7, 11] |
如迭代器的长度不一致,缺失的项将用None代替:
|
1 2 3 4 5 |
>>> map(lambda x, add: x + add, (2, 4, 5), (1, 3)) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 1, in <lambda> TypeError: unsupported operand type(s) for +: 'int' and 'NoneType' |
如果function为None,将用 identity function 代替(好像就是直入直出)。
max(iterable[, args…][, key])
如果只给一个参数,就返回iterable里最大的项;如果是多个参数的话,则返回参数里最大的项。
|
1 2 3 4 |
>>> max("abcd") 'd' >>> max(1, 2, 3) 3 |
额外的key参数,是用于比较的函数,比如,下面这个可以得到各项除3的余数最大的一个:
|
1 2 |
>>> max([1, 2, 3, 4], key=lambda x: x % 3) 2 |
min(iterable[, args…][, key])
同上,求最小值。
next(iterator[, default])
依次返回迭代器iterator的项。当iterator没有更多的项时,如果有default参数,则返回default,否则抛出StopIteration例外。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
>>> a = iter(range(3)) >>> next(a) 0 >>> next(a) 1 >>> next(a) 2 >>> next(a) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>> next(a, "No More Item...") 'No More Item...' |
object()
返回一个空的对象,但是此对象会有一些公有的属性:
|
1 2 3 |
>>> o = object() >>> dir(o) ['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__'] |
oct(x)
将任意精度的十进制整数x转换成八进制。
open(filename[, mode[, bufsize]])
打开文件,返回一个文件对象,如果文件打不开,将抛出IOError错误。
filename参数,是要打开的文件名。
mode参数是打开方式,通常是'r'表示读,'w'表示写(如果已存在则会覆盖),'a'表示追加。缺省为'r'。另外,缺省使用的是文本模式,会把'\n'转成系统相关的换行符,如果要避免这个引起的问题,需要在各个模式后面加一个'b'表示使用二进制模式。另外还有些’+uU’之类的模式,不常用,也就不介绍了吧。
可选的bufsize参数表示缓冲区的大小。0表示不缓冲,1表示行缓冲,其他正数表示近视的缓冲区字节数,负数表示使用系统默认值。默认是0。
ord(c)
给定一个长度为1的字符串或者unicode字符,返回该字符的ascii码或者unicode码,前一种情况是chr()的反函数,后一种情况是unichr()的反函数。
pow(x, y[, z])
返回x的y次方,也就是x**y。如果有z的话,返回x的y次方除z得到的余数(这个比pow(x, y) % z更高效,这点可以看我写的欧拉工程第48题的代码,之前很慢,现在很快)。
如果第二个参数是负数的话,将返回浮点型的数据,而且这个时候不能有z。
print([object, …][, sep=’ ‘][, end=’\n’][, file=sys.stdout])
输出一个或多个object到file,中间用sep间隔,并在结尾加上end。
后3个参数如果给出的话,必须用keyword arguments的形式,也就是必须指定参数名,否则将一概被视为object的一部分而被输出。
需要注意的是和python 2.6前的print关键字的区别。
property([fget[, fset[, fdel[, doc]]]])
返回一个属性,参数分别是获取、设置和删除的函数外加doc string,看例子吧:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
>>> class C(object): ... def __init__(self): ... self._x = None ... def getx(self): ... print "OK. give you:", self._x ... return self._x ... def setx(self, value): ... print "Now x is:", value ... self._x = value ... def delx(self): ... del self._x ... x = property(getx, setx, delx, "I'm the 'x' property.") ... >>> a = C() >>> a.x = 123 Now x is: 123 >>> print a.x OK. give you: 123 123 >>> help(a.x) OK. give you: 123 >>> help(C.x) #这里可以看到I'm the 'x' property. |
range([start], stop[, step])
方便地产生一个包含等差数列的list,如果忽略start,则默认为0;如果忽略step,则默认为1。经常被用于for循环里。注意返回的结果并不包含stop。
raw_input([prompt])
从输入读入一行字符串,结尾的回车将被去掉。如果提供了prompt参数,将做为输入的提示符。
reduce(function, iterable[, initializer])
将两个参数的function函数循环应用到迭代器的各项,例如reduce(lambda x, y: x+y, [1, 2, 3, 4, 5])相当于((((1+2)+3)+4)+5)。如果提供了可选的initializer参数,则会将它放在迭代器的前面进行运算。
reload(module)
重新加载之前已经导入的模块。当你在设计一个模块,并用外部编辑器更新了它的代码时,可以用reload重新导入此模块,来验证模块的正确性。
reload执行时候的具体细节这里就不描述了。
repr(object)
返回一个尽量包含object的信息的字符串,其实交互式python解释器,在输入一个对象回车的时候,就是返回对象的repr值。
对于很多常见的对象,返回的值都尽可能地使得能够被eval解释并返回对象本身;另外的就尽量包含所在的域信息和类型或者地址等。
一个类可以通过__repr__()方法自定义repr的返回值。
reversed(seq)
返回一个倒序的迭代器。seq要么支持 __reversed__() 方法,要么支持取项的操作(也就是支持__len__()方法和从0开始的整数值的__getitem__()方法)。
例子:
|
1 2 3 4 |
>>> reversed(range(5)) <listreverseiterator object at 0x80a658c> >>> [i for i in reversed(range(5))] [4, 3, 2, 1, 0] |
round(x[, n])
将浮点数x四舍五入取整到小数点后n位小数。n的默认值是0,也就是取整。
set([iterable])
由迭代器iterable返回一个集合对象,集合中的元素是随机顺序,但是不重复的。此函数在去掉列表的重复项的时候,特别有用:
|
1 2 3 4 5 6 7 |
>>> l = [1, 2, 3, 2, 4, 3] >>> set(l) set([1, 2, 3, 4]) >>> list(set(l)) [1, 2, 3, 4] >>> ''.join(set("hello")) 'helo' |
setattr(object, name, value)
此函数和getattr()配合使用,setattr(x, 'foobar', 123)相当于x.foobar = 123。
slice([start], stop[, step])
返回一个分片对象,分片对象就只包含了start, stop, step这3个信息,它在python内部和一些第三方库中广泛被使用,其实类似a[1:3]这样的操作也会生成分片对象。如果省略start和step,将默认为None。
可以看到下面两者其实是等效的:
|
1 2 3 4 |
>>> range(5)[slice(1, 4, 2)] [1, 3] >>> range(5)[1:4:2] [1, 3] |
sorted(iterable[, cmp[, key[, reverse]]])
返回一个排序后的列表,用于排序的元素来自iterable,后面的参数控制排序的过程。
cmp是自定义的比较函数,接受两个参数,返回负数表示第一个参数较小,返回0表示两者一样大,返回正数表示第一个参数较大。
key可以理解为每个参数的求值函数。如果提供了key,则在比较前,先对每个先用key进线求职,对结果再进行排序,但是返回的排序后的结果还是之前的值。
reverse如果是True,则按降序排列,默认是从小到大的升序。
看例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#正常的排序 >>> sorted([1, 5, 3, 4, 6]) [1, 3, 4, 5, 6] #倒序 >>> sorted([1, 5, 3, 4, 6], reverse=True) [6, 5, 4, 3, 1] #提供了key,结果是除3的余数谁最小,谁就排前 >>> sorted([1, 5, 3, 4, 6], key=lambda x: x%3) [3, 6, 1, 4, 5] #用cmp实现的版本 >>> sorted([1, 5, 3, 4, 6], cmp=lambda x,y: x%3 - y%3) [3, 6, 1, 4, 5] |
值得注意的是,虽然cmp和key都可以实现上面的除3余数排列,但是因为cmp要对每次比较的两个元素都调用一次函数,所以,效率不如key来得高。
staticmethod(function)
返回一个静态方法function
要声明一个静态方法,需要使用如下的语法:
|
1 2 3 |
class C: @staticmethod def f(arg1, arg2, ...): ... |
静态方法可以被类本身调用(例如:C.f())也可以被类的对象调用(例如:C().f())。
str([object])
返回一个精确可打印的字符串,来说明object。和repr(object)不同,str(object)返回的字符串不一定能被eval()执行来得到对象本身,str(object)的目标只是可打印和可读。
sum(iterable[, start])
对iterable在start做为初值的基础上进行累加。start的默认值为0。
注意此方法不能对字符串进行相加(连接)操作,连接字符串还是用''.join(sequence)好了。另外,sum(range(n), m)等价于reduce(operator.add, range(n), m),要更精确地对浮点数进行累加,请使用math.fsum()。
super(type[, object-or-type])
返回一个指代type的父类或者兄弟类的对象,可以用这个对象间接地调用父类或者兄弟类的方法。在有复杂的类继承关系结构的时候,会很有用。用到的时候可以自行研究下这文章。
tuple([iterable])
返回一个tuple对象(元组),元素来自iterable。如果省略参数,将返回空的元组。
type(object)
返回object的类型,返回值本身是个“类型对象”。注意,进行类型判断建议使用isinstance()函数。
|
1 2 3 4 5 6 7 8 |
>>> type(1) <type 'int'> >>> type(type(1)) <type 'type'> >>> type(1) == int #非常不建议这样的使用方法。 True >>> isinstance(1,int) #建议这样使用。 True |
type(name, bases, dict)
不同于上面那个一个参数的type,这个方法用于快速构造一个类,传入的3个参数将分别转化为所得到的类的__name__,__bases__和__dict__。
例如,下面这两个X是等价的:
|
1 2 3 4 |
>>> class X(object): ... a = 1 ... >>> X = type('X', (object,), dict(a=1)) |
unichr(i)
返回一个单个字符的unicode串,此字符的unicode码值为i。对于Unicode,此函数也是ord()的反函数。i的范围由python解释器的编译环境决定。
unicode([object[, encoding[, errors]]])
返回一个代表object的unicode字符串。
如果给定了encoding和/或errors,将用ascii或者encoding指定的编码对object进行解码,在遇到解码错误的时候,errors的值将影响函数的下一步动作:如果errors的值是'strict'(默认值),将会抛出ValueError错误;如果errors的值是'ignore'将会忽略错误,继续解码;如果errors是'replace',将使用U+FFFD来替换当前字符。
看个例子,我的utf8环境下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
>>> unicode('我是bones7456', encoding='utf8') u'\u6211\u662fbones7456' >>> print unicode('我是bones7456', encoding='utf8') #可见解码成功 我是bones7456 >>> unicode('我是bones7456') #不指定编码方式,将默认使用ascii解码,失败了。 Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128) >>> unicode('我是bones7456', errors='ignore') #忽略失败,可以得到英文数字部分 u'bones7456' >>> unicode('我是bones7456', errors='replace') #替换的话,会加上一堆???哈哈。 u'\ufffd\ufffd\ufffd\ufffd\ufffd\ufffdbones7456' >>> print unicode('我是bones7456', errors='replace') ������bones7456 |
如果没有后面的俩参数,unicode()的行为类似于str(),只不过返回的unicode字符串而已。
如果,object对象提供了__unicode__()方法,将调用此方法来返回一个可被用户自定义的unicode串。
vars([object])
如果省略object,vars()和locals()类似,如果object是模块、类、类的对象或者其他还有__dict__属性的对象的话,就返回它的__dict__。
xrange([start], stop[, step])
此函数和range()非常类似,但是返回的不是一个列表,而是一个xrange对象。xrange对象在被引用时,也能生成列表的各项,但是这些项不是同时存在于内存里的。xrange和range比的优势是更小巧,更快。
zip([iterable, …])
哈,说到这个函数,我还给python官方文档提过一个bug,因为之前版本的文档的示例代码有点小问题,前因后果可以看这里。
zip函数返回一个元组的列表,第i个元组,就包含了每个iterable的第i项。如果参数的各iterable不一样长,会别截取到最短的值,这个值也就是结果列表的长度。
然后,zip内如果有个 * 开头,将会执行逆运算(unzip),示例:
|
1 2 3 4 5 6 7 8 |
>>> x = [1, 2, 3] >>> y = [4, 5, 6] >>> zipped = zip(x, y) >>> zipped [(1, 4), (2, 5), (3, 6)] >>> x2, y2 = zip(*zipped) >>> x == list(x2) and y == list(y2) True |
__import__(name[, globals[, locals[, fromlist[, level]]]])
此函数被import语句调用。代码中很少会用到这个函数,除非你要import的模块名是运行时才可知的。就不详述了。
我架设的ubuntu源
9月19日,是2009年的软件自由日,在这个比较特殊的日子,我要送给广大ubuntu爱好者一份礼物──一个新的ubuntu源。
正如我刚才的那篇文章所说,这个源的特点就是能保证全和新。至于速度还要看大家的测试结果(应该不会太差)。
这个源是在杭州电信的,百兆共享带宽,不知道网通用户的速度如何。
希望在9.10发布的时候,就能够加到ubuntu官方源列表里。这样用起来就更方便了。
其他就先不说了,大家可以通过这几个域名访问:
http://ubuntu.srt.cn/
http://ubuntu.hzlug.org/
http://u.srt.cn/
谷歌音乐下载器
之前有很多下载baidu mp3的程序,有bash的,java的,python的,其中也包括我这个.
但是baidu的歌曲都是用程序收集自网络的,所以排行榜的歌曲质量就没有保障了,下载下来的歌曲ID3信息可谓一塌糊涂,而且还可能下载到网友自己翻唱的歌或者其他杂七杂八的东西,严重影响我们的听觉神经.
而谷歌(不是google)最近推出了谷歌音乐搜索,联合top100,也推出了类似百度榜单的音乐排行榜.但不同于百度的是,谷歌里的歌曲都是收集整理过的,不会有死链,质量也很不错,而且,对于最终非商业用途的个人用户而言,是不存在版权问题的(但我不确定批量下载下来的有没有版权问题.请用户自行考虑.).
所以我顺势就推出了这个谷歌音乐下载器 .
目前程序还很简陋,没有图形界面,也没有很多可以设置的地方.运行程序只会把”华语新歌”这个榜单的100首歌下载到本地当前目录.所以仅供有兴趣尝鲜的同学测试使用.但是以后,我打算把这个程序做成有图形界面的,可以试听/下载/播放的一个整合工具,哈哈.请大家多多关注吧.
PS:有人说这类工具还是不要发布出来,小范围流传下比较好,因为发布出来以后,很可能遭到google的封杀.这说法其实也有些道理,但是我想想,如果谷歌真的因为这个来封杀我,我也够有面子的,嘿嘿.所以我还是按照Google的Project hosting页面所说的做了: Release early, release often
e-file 根据文件名查询gentoo包的脚本
一直想在gentoo下实现一个类似ubuntu的apt-file的功能,幸好已经有 http://www.portagefilelist.de 这个网站了,就花了2小时写了个小脚本直接到这个站取数据了,感觉效果还可以,先发出来,算是预览版吧,以后会再完善的.
输出格式参考了 eix ,代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
#!/bin/sh #AUTHOR: bones7456 (bones7456<at>gmail<dot>com) #VERSION: 20081120 ##License: GPL #e-file is like apt-file for gentoo, but data is online if [[ $# -ne 1 ]];then echo "Usage: `basename $0` filename" exit 1 fi URL="http://www.portagefilelist.de/index.php/Special:PFLQuery2?file=$1&searchfile=lookup&lookup=file#result" w3m -dump -cols 3000 $URL | awk ' BEGIN{ FLAG=0 FOUND=0 } { if($1=="dir" && $2=="package"){ FLAG=1 next } if($1=="Retrieved" && $2=="from"){ if(FOUND){ for(i in ver){ split(i,ii,/\//) printf("%c[%d;%d;%dm* ",27,2,0,32) printf("%c[0m%s/",27,ii[1]) printf("%c[%d;%d;%dm%s\n",27,2,1,29,ii[2]) printf("%c[%d;%d;%dm\t",27,2,0,32) printf("Available versions:\t%s\n",ver[i]) printf("\tMatched File:\t\t") printf("%c[0m",27) printf("%s\n\n",file[i]) } }else{ print "No matches found." } exit } if(FLAG==1 && NF!=0){ ver[$1 "/" $2]=$NF " " ver[$1 "/" $2] file[$1 "/" $2]=$3 "/" $4 FOUND=1 } }' |
截个图:

脚本下载地址
python多处理器编程
由于上次做的那个一维随机游走程序,虽然简单,但是大数据的时候很费CPU,而且我注意到我的双核处理器始终只有一核是处于满负荷工作,另一个核的性能没有得到发挥.而且我也试过把同样的程序放到一个8核的服务器上运行,结果解题的速度也只是比我本本快那么一点点,估计也只是那服务器的CPU主频(2GHz)比我的1.86GHz略高而已,完全没有发挥出他8核的优势.
所以马上想到了python有没有多处理机的机制,上网google一下,发现由于python是解释型的语言,而Python解释器使用GIL(全局解释器锁)来在内部禁止并行执行,正是这个GIL限制你在多核处理器上同一时间也只能执行一条字节码指令.猜想这个GIL也是当初为了设计解释器方便而搞的吧.而且据说python 3.0 里面已经改进了,默认有了多处理器编程的库了.但是毕竟现在python3.0还没有流行起来,那么现在有没有变通的方法呢?
当然有~不然我就不会写这文章了嘛~
Parallel Python 这个库,正是为了解决我们的问题而设计的,而且它不仅可以多核处理器协同工作,还可以通过网络集群运行呢,嘿嘿.
下面的中文介绍来自这里:
1 简介
PP 是一个Python模块,提供了在SMP(多CPU或多核)和集群(通过网络连接的多台计算机)上并行执行Python代码的机制。轻量级,易于安装,并集成了其他软件。PP也是一个用纯Python代码实现的跨平台,开放源码模块。
2 功能
* 在SMP和集群上并行执行Python代码
* 易于理解和实现的基于工作的并行机制,便于把穿行应用转换成并行的
* 自动构造最佳配置(默认时工作进程数量等同于系统处理器数量)
* 动态处理器分配(允许运行时改变工作处理器数量)
* 函数的工作缓存(透明的缓存机制确保后续调用降低负载)
* 动态负载均衡(任务被动态的分配到各个处理器上)
* 基于SHA的连接加密认证
* 跨平台移植(Windows/Linux/Unix)
* 开放源代码3 开发动机
现代Python程序已经广泛的应用在商业逻辑,数据分析和科学计算等方面。其中广泛应用着SMP(多处理器或多核)和集群(通过网络连接的多台计算机),市场需要并行的执行的Python代码。
在SMP计算机上编写并行程序最简单的方法是使用多线程。尽管如此,使用 ‘thread’ 和 ‘threading’ 模块仍然无法在字节码一级实现并行。因为Python解释器使用GIL(全局解释器锁)来在内部禁止并行执行。这个GIL限制你在SMP机器上同一时间也只能执行一条字节码指令。
PP 模块正是为了解决这个问题而来,提供简单的方式实现并行Python应用。 ppsmp 在内部使用 进程 和 IPC (进程间通信)来组织并行计算。并处理了所有内部的细节和复杂性,你的应用程序只需要提交工作任务并取回结果就可以了。这也是编写并行程序的最简单的方法。
为了更好的实现,所有使用 PP 的软件通过网络来连接和协作。跨平台和动态负载均衡使得 PP 可以轻松组织多平台、异构的集群计算环境。4 安装
任何平台:下载模块压缩包,解压,运行setup脚本:
python setup.py install
Windows:下载和执行安装包。
另外,debian和ubuntu用户,也可以通过apt直接下载安装,包名是 python-pp ,但是由于版本比较老,是 1.5.4 版本的,而最新的是 1.5.6 ,所以官方页面上的示例代码可能运行不了,会出现以下错误提示:
Traceback (most recent call last):
File “testpp.py”, line 46, in
job_server = pp.Server(ppservers=ppservers)
File “/var/lib/python-support/python2.5/pp.py”, line 312, in __init__
raise ValueError(“secret must be set using command-line option or configuration file”)
ValueError: secret must be set using command-line option or configuration file
原因是代码的不兼容性,解决办法就是找到 pp.Server 那行,多加一个参数,如下:
|
1 |
job_server = pp.Server(ppservers=ppservers,secret="") |
由于这个库,包装得不错,所以用起来也比较简单,基本上看了示例代码,就会了,使用方面也就不多介绍了,如果有可能的话,我倒是想写个gentoo的ebuild文件,嘿嘿.
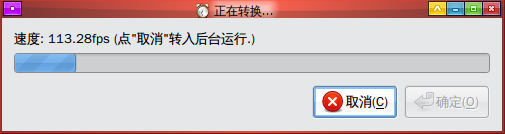
给 iPod 转视频的脚本
由于新买了个 iPod touch,这几天认真钻研了下它的视频格式,搞了个nautilus脚本,使用mencoder做后端.
以后想把某个视频文件转成iPod的格式的话,直接在 nautilus 里面右键点文件-脚本-toIpod 就可以搞定了.
脚本的特点:
* 借助mplayer的强大,支持N多的源格式(已测试: avi rmvb mov flv).
* 支持srt/ass格式的外挂字幕.
* 自动缩放画面比例到适合ipod touch的480*320,如果是 ipod shuffle 之类的话,可以自己修改下脚本.
* 可视化的进度提示
* 转换速度较快
* 默认保存到当前目录,可修改脚本,输出到统一目录,方便管理.会自动加上 _ipod.mp4 的后缀名.
使用方法,保存以下脚本到 ~/.gnome2/nautilus-scripts/toIpod ,并加可执行权限…或者这里下载
PS: 如果压缩出来的字幕有乱码,请参照我以前的文章,建个 ~/.mplayer/mencoder.conf 文件,写上一行 subcp=cp936 就好了.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#!/bin/bash #filename: ~/.gnome2/nautilus-scripts/toIpod #Copyright (c) 2008 bones7456 (bones7456<A>gmail<D>com) #License: GPL #version 20081101 #用于将视频转成 ipod touch / iphone 格式.右击文件使用 SAVEDIR=`pwd` #SAVEDIR="/data/movie" INFILE="$1" PWD=`pwd` CMD="mencoder -of lavf -lavfopts format=mp4 -oac lavc -ovc lavc " CMD+="-lavcopts aglobal=1:vglobal=1:vcodec=mpeg4:vbitrate=600:acodec=libfaac:abitrate=128 " CMD+="-af lavcresample=22050 -vf dsize=480:320:0,scale=0:0,expand=480:320,harddup -ofps 25 -srate 22050 " P="没有找到对应的字幕." if [[ -f "${INFILE%.*}.srt" ]];then CMD+=" -sub ""\"$PWD/${INFILE%.*}.srt\"" P="找到字幕文件: ""${INFILE%.*}.srt" elif [[ -f "${INFILE%.*}.ssa" ]];then CMD+=" -sub ""\"$PWD/${INFILE%.*}.ssa\"" P="找到字幕文件: ""${INFILE%.*}.ssa" elif [[ -f "${INFILE%.*}.aas" ]];then CMD+=" -sub ""\"$PWD/${INFILE%.*}.aas\"" P="找到字幕文件: ""${INFILE%.*}.aas" fi CMD+=" -o ""\"$SAVEDIR/${INFILE%.*}_ipod.mp4\""" ""\"$PWD/$INFILE\"" P+="\n\n保存目录: $SAVEDIR" P+="\n\n是否继续?" #echo "$CMD" >> ~/toIpod.log if ! zenity --question --text "$P" ; then exit 0; fi eval "$CMD 2>&1" |\ while read line; do echo $line |\ awk -F '[ :\(\)%]+' '/^Pos/{print "# 速度:",$5,"(点\"取消\"转入后台运行.)";print $4}' ; done |\ zenity --progress --title "正在转换..." --percentage=0 --auto-close --width=500 |
截图:
sssh 快速ssh登陆脚本
此脚本对于那些需要经常ssh登陆远程服务器的朋友应该有点用处.尤其是需要中转服务器ssh 2次以上的.
脚本功能:
将服务器IP和密码保存于文本文件中(明文保存,安全性要自己保证),方便登陆,支持多次ssh中转,支持服务器编码自动转换,支持某个用户名的通用密码.
使用方法:
最好将脚本保存在PATH变量包含的路径下,建议保存于 ~/bin 并确保此目录在 PATH 中.
编写 ~/.pass 文件,并执行 chmod 600 ~/.pass
安装 expect 包.
.pass文件的写法
1.最简单的,可以在文件中写下如下一行:
name=hostA usernameA@IP-A passwordA
就可以使用 sssh hostA 登陆此服务器了.
2.中转登陆:
name=hostA usernameA@IP-A passwordA
name-hostA=hostB usernameB@IP-B passwordB
执行 sssh hostA hostB 就相对于先登陆hostA,然后在hostA上登陆hostB
同理,理论上可以中转N次,hostA->hostB->hostC->hostD…,嘿嘿…
3.使用通用用户名的密码.
这是用于这样的例子:有N个服务器,都开通了一个通用用户名(例如:view用户,只有很低的权限),这些view用户的密码都是同一个,而且会定期同步修改.这种情况下,如果修改了view密码的话,.pass文件就要修改N个密码了,为了避免这样的麻烦,可以使用通用用户名和密码功能:
usualName view
usualPSW password-of-view
name=hostA view@IP-A
name=hostB view@IP-B
name=hostC view@IP-C
这样就可以直接用 sssh hostA , sssh hostB 登陆了.
可以看到,这里省略了第3列的密码字段.此法同样适用于多级登陆的服务器.
4.指定服务器使用的编码
usualName view
usualPSW password-of-view
name=hostA usernameA@IP-A passwordA gbk
name=hostB view@IP-B | gbk
在某行服务器的后面(第4列),加上 gbk,就可以指明该服务器使用的是gbk,登陆了以后不会出现乱码了.
如果某行使用了通用用户名和密码的话,为了不致引起混乱,密码那列需要加个 | (竖线)占位.
5.使用通用编码
usualCODING gbk
加上此行,对于没有指定编码的服务器,将默认使用gbk编码.
下载:
由于脚本贴在这里会出现半角引号变全角的状况.所以,请直接在这里下载 这里下载.
哈哈,没想到,脚本没几行,写个说明倒是一堆了…
新的PS1
特点就是命令正常结束时不会显示退出码,但当退出码非零时,就会以红色醒目的显示出来.
由于代码贴到这里,里的引号都会全角的,所以不如和预览效果一起贴个截图:

离线中文维基(wikipedia)
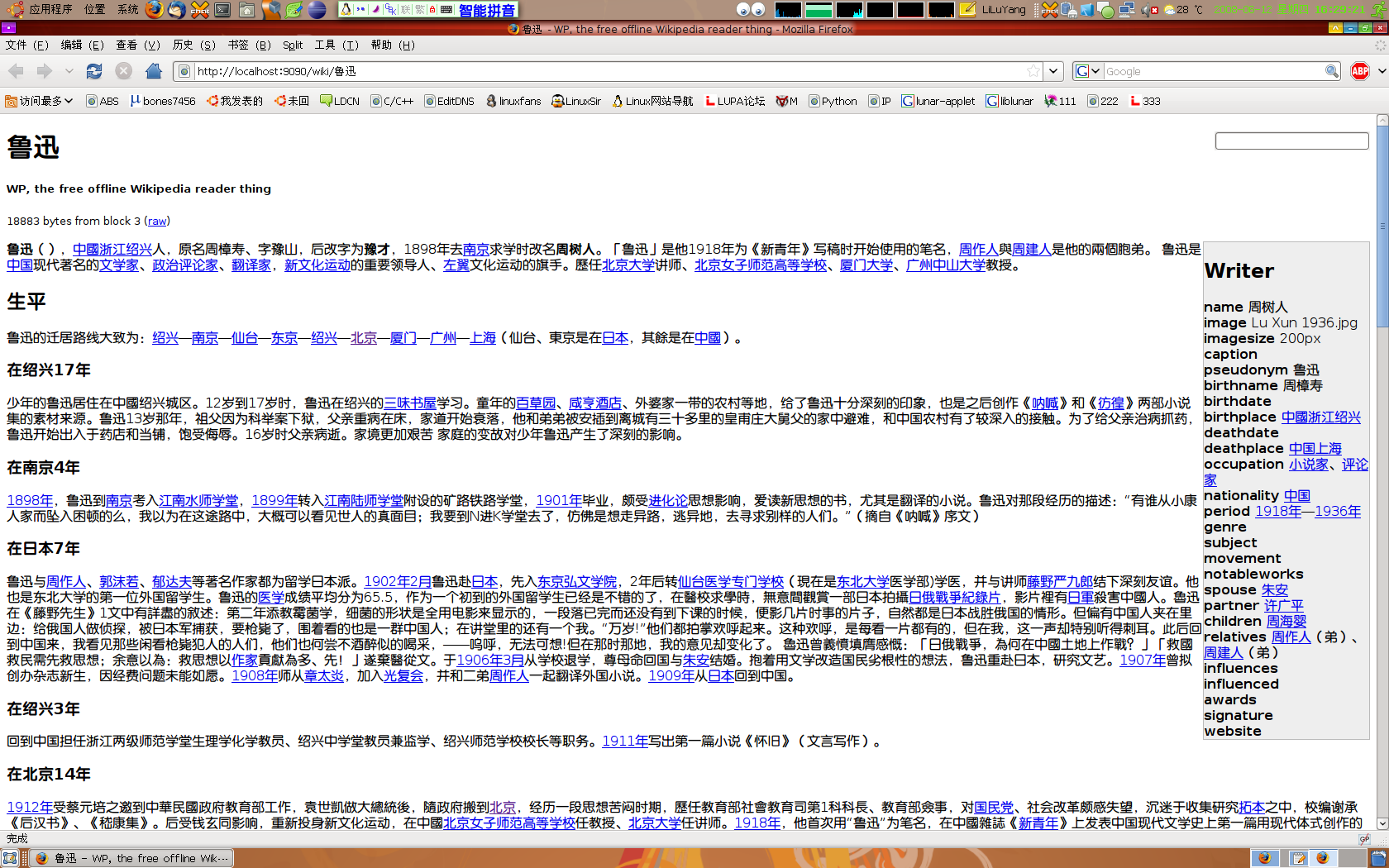
本来作者的本意是开发一个离线的 iphone/ipod 用的wikipedia的,电脑上的只是为了方便调试用而已,而且但是由于众所周知的原因,内地用户访问中文维基并不是很方便,于是,我觉得电脑上的离线维基便更加有意义了.
注意: 本项目目前出于刚刚起步阶段,维基内容只能显示文本,图片/目录以及一些高级的格式还暂时不支持(别问我以后会不会支持,我也不知道),当然繁简体转换之类的高级功能肯定也没有.
使用方法:
先安装 ruby libinline-ruby mongrel rubygems libbz2-dev 这几个包,ubuntu用户可以直接apt-get,其他发行版估计就要自己解决这几个包的安装问题了.
完了以后,下载 http://ftp.ubuntu.org.cn/home/bones7456/zh_wiki.tar.gz(约180M) 密码在这里,解压到任意目录,然后运行里面的 startserver.sh ,即可用过浏览器访问 http://localhost:9090/
备用下载地址: http://linuxfire.com.cn/~lily/zh_wiki.tar.gz
md5sum:
ac2e9f38492c86d22258f0a853c1c4b5 zh_wiki.tar.gz
数据版本: 20080608, 包含页面文字和链接,不包含图片和编辑历史等.
主页: http://code.google.com/p/wikipedia-iphone/
数据版权参见: http://zh.wikipedia.org/w/index.php?title=Wikipedia:%E5%85%B3%E4%BA%8E&variant=zh-cn
最后,效果截图来个(点击放大):